
Comprehensive malware research can be a difficult task. Before reversing and constructing the timeline, the reverser needs a significant set of samples of the malware from multiple stages of its development. Finding similar samples can be quite difficult, as comparing files at scale is computationally expensive and often unfruitful. Naturally, having a problem with scale and malware, we brought out the big guns: machine learning.
First things first - I am not a Data Scientist. I am a Security Researcher slowly learning basic machine learning principles. I found it imperative to start learning how to leverage machine learning in my research after seeing the seemingly boundless possibilities of machine learning from the talented Data Scientists we have here at Cylance.
For a Security Researcher such as myself, I often find one of my more challenging problems is searching for similar samples of malware I already have so I may fully analyze a malware family over time. Using YARA signatures can be useful, but they are only as good as the signature created. Using fuzzy hashes like ssDeep can be helpful, but they are extremely limited due to scaling issues despite recent optimizations (https://www.virusbtn.com/virusbulletin/archive/2015/11/vb201511-ssDeep).
Spring Dragon APT
Palo Alto Networks released a report on the Spring Dragon threat actor earlier this year (http://researchcenter.paloaltonetworks.com/2015/06/operation-lotus-blossom/). The report provided great detail on the Lotus Elise malware (this malware is not targeted at motor vehicles, just named after them), which was used as a backdoor. Interestingly enough, the report only briefly mentions the Lotus Evora malware, but provides few details and indicators of compromise (IOCs).
This Evora malware seemed like a great candidate for a write up, as very few details were publicly available, and there were few IOCs. After obtaining some initial Evora samples, I started my analysis, working towards dumping configuration details from samples, as well as determining functionality (I will cover these in a future blog post).
After my initial analysis, I came to the conclusion that I had too few samples. Even after doing some YARA-based searches, it was clear there had to be more than the samples I already possessed. At this point, I consulted with a number of our machine learning gurus, who suggested using a centroid to find more samples.
Centroids and Distances
At this point, I’ll take a step back to describe the concepts behind a centroid and why this would be useful.
During our normal processing of a file to determine whether it is benign or malicious, we extract millions of “features” for every file. Features are a set of attributes which describe a file, and can range from the number of resources to the entropy in a particular section. When we extract all the features from a file we are processing, we end up with a “vector”, or an array of numbers representing all the features from that file.
A centroid, in this case, is represented by a vector that describes the central point of a set of vectors derived from files. A radius which represents the maximum distance from the centroid that a similar sample will fall into can then be defined.
Now one may be asking themselves, “Why is he going on about distance?” Consider the following:
To determine the distance between two points on a 2D plane, we use the Pythagorean theorem (https://en.wikipedia.org/wiki/Pythagorean_theorem). It is highly probable you learned this in grade school:
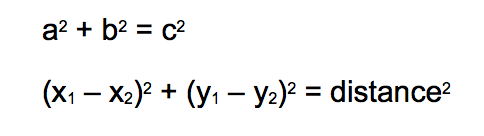
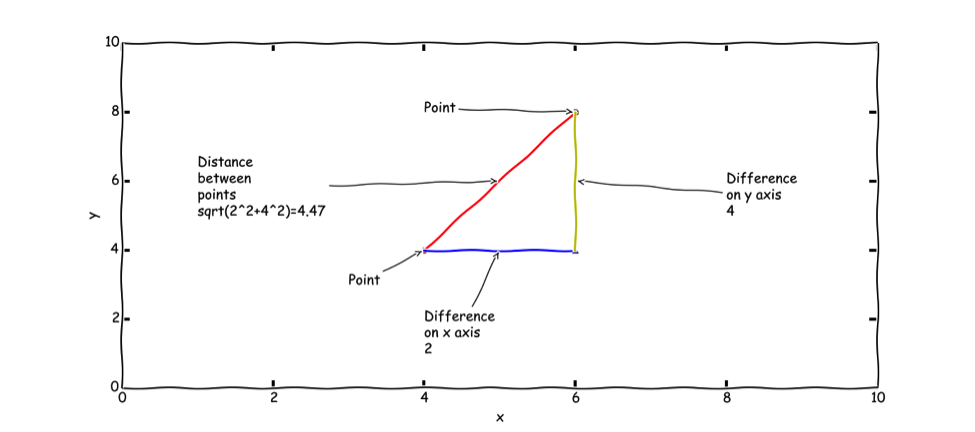
Essentially, if we square the difference between the points on the horizontal dimension and add that to the square of the difference between the points on the vertical dimension, we have the distance squared. Take the square root, and you have your distance.
If we treat each of our features as dimensions, we should be able to find the distance between vectors to determine if they fall within our radius. The high dimensional distance calculation we will use for this is referred to as Euclidean distance (https://en.wikipedia.org/wiki/Euclidean_distance), which is remarkably similar to Pythagorean’s Theorem.
To search within the centroid, we calculate the distance between our centroid and each file we have processed on the relevant features, and consider them similar to our original files if the distance is less than our radius.
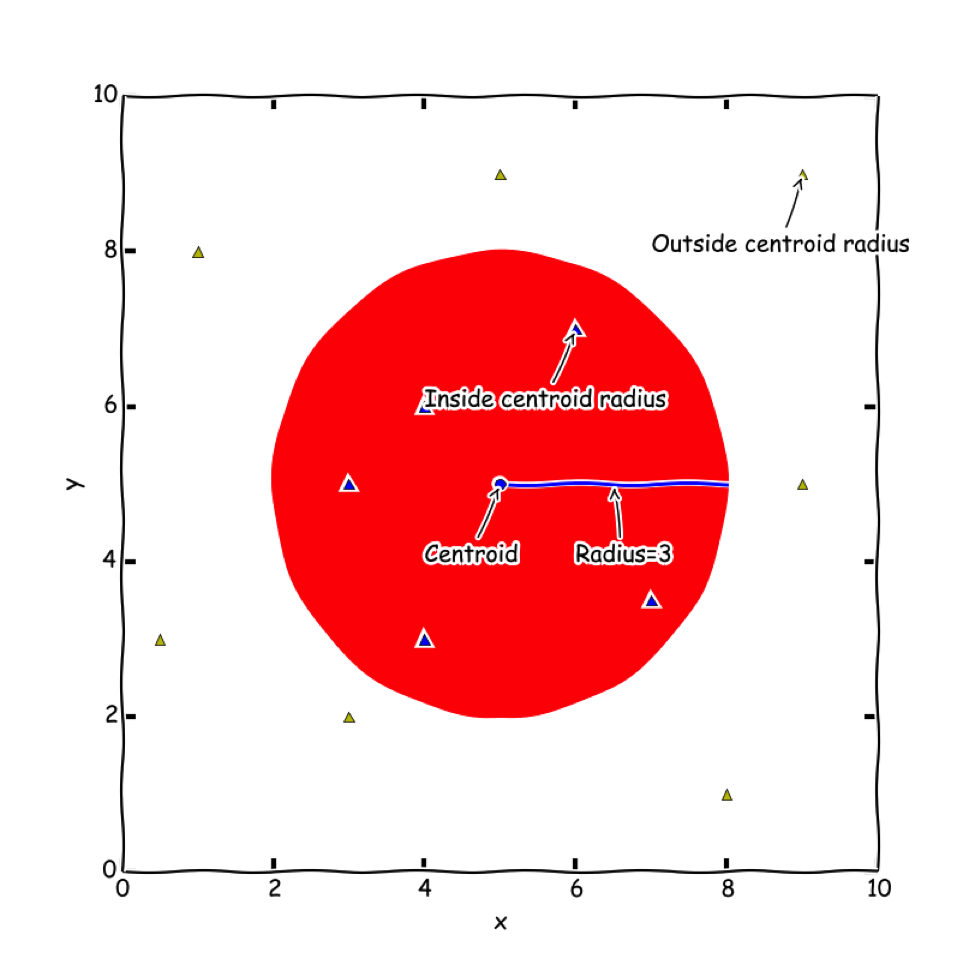
Evora Centroid
That is how we use a centroid to search, but now we need to generate the centroid, which can be quite difficult. I am dedicated to updating my knowledge of machine learning any time I am able to do so, therefore, I took this opportunity to throw myself into the deep end.
To build this centroid, I first tried to find a set of features that would allow me to search with a radius of 0. This means an exact match of feature values across all relevant features. This was easy enough to determine, as I simply looked for any features that were the same across all Evora samples. Luckily for me, I was able to find a significant number of features that were an exact match across my Evora samples.
After testing this centroid against a set of unrelated samples locally, the centroid was ready to run against our collection of samples. Our expert data scientist loaded the centroid and returned a surprising set of hashes.
Finding Evora and Elise in the Results
After an initial inspection of the files that came back, I was surprised. Not only were Evora samples returned, but also a number of Elise samples! The centroid-based search was not only viable for determining other Evora samples, but additionally, other malware from the same threat actor. The efficacy of machine learning, even when used by an amateur such as myself, can be quite high.
I now had 28 Evora samples (including my original set) and 39 Elise samples (all found with machine learning).
Evora and Elise
I plan on writing a follow-up blog post detailing both Evora and Elise.
Conclusion
While I am not a Data Scientist, I continually find that machine learning is a powerful tool. It can have a steep learning curve, but is more than worth the effort to learn. Information security has no lack of problems to solve, and I have no doubt that machine learning is one of the tools necessary to solve the more difficult ones.
IOCs
Evora SHA256s:
00a9466358d2b716be215f856c44e2b62df64b29a4d04aaa1ef0a194d825313f
0a372eb55d5bc91be510a4d9084a5c15ec22c3b066fe226994566a136564a2ec
11107f6f1f41466ae9e01cd6fc3a3c615e1fa8ee8f7e786a2f7b5b371434af9c
151f6e3a052ab72e6ac043922415126d19a5085dda1ea70aa7d5c345ef4c905a
23753c260e48fd092423aceb6300a9b858eeaa113f6f7040305edb545f4da35f
349d2e0a3be5e567416c1a5abb1a01ddb0e31f4c80d4543fad1a5766fd3b5002
3d059628f80ca8aa1977c0be001a1c11919f76d983139561e7955af645fa979e
435590115a89427b28f4b7d90850cf92751e23358f2d198bab1d7a22ff793fba
52e896c6d22929ade6e0cdc54b6a27afd960658955b8ff92996304820c3a03e4
5e2de83e9b24ed78f38b7189c3505aee5d710bc1a7be473e96e0aa3630112b84
6c720a4df2acd644bf7153a0c12c70db4a354b20ed14500bbcc91b3e8eaac522
7d24387e79a537b17ad4b4d19e24a0010034689d3e2b9812f26d1ad579d21cbe
81a0f80edf8d41f97d799a81c67e9c8930abaece59a73c1d097ee576c0c8a15c
89db78dcf95e887ddf0818016fa5988e44d23d87c6922bd81dfb3c68ef6cfe93
981df8ab5eb36467b595a86a0d6905dc57151d66f4a0a64cfc6734c33d0a4cbe
aacaf259d0e4d6527158a3f97ccf0029abcdefba85c264940fbc2267d59659eb
b877bc5b9b925fb0056f4b140865c0a89d3c0a31701a6e4feb1b73d2065420d3
cb92dbfd904821e8e66662734c0bb82ae63879d1f5fa1ab0ee8e60e4052a70ae
d21022fbee8a919c43fb35d070a3b16832ea565aa6a0b81fb09d49a93e4a7ee9
da4cbc222be7c51b2cc3d358e03a8f36cc80b7b27243526037d2d2740c48f7a7
dbfd0240511cc26767f5b747df2b043334535a36fec03c6bdce0521571d8d52e
dd0ec1712f8b759b5d4b52f7da9aec9f956a93639a00979790e01caeb5494c09
e08c0173671c7defbef03d9101d8d26f223e8d40ba7bfa6232fea40ea6545c0d
e0f92aff03c3aae95ad8a34ca64422fe36e2c491379a5a3a403a57ae1ec72dc7
e905d54784f2ae2cd040f9bcb792efbdb675207717ff422d7258446389b44165
efc9ed5d0b554f0cdda8ed8feaeb7cbdaadf46ac3021a2eb3fd532632662fbd0
f0a9c3e055aa54cfdd21dc1028ffbc74ee5da56a81039cb1723747dcfa3c150c
f16d6caa1d454fd2fa6b2d959f1b3664b46dcbb88fff9b14bc23bff1ec667b41
Evora MD5s:
080eda5a11d93703470ec5a42498aeee
0ad154de647b7ab3790ec6e439a106f8
30b788d61843434410a3b3f882c9e658
313303f8b207547c1065110233a38a93
39951cafa1561fe49938c652be57d927
42126a340bb07ab6c23a1c2d43e7adda
4311cc3b92f4537e75289a44c2b3800e
448ce6d025da1a71d107093963be74e0
4f350cf78b0875dd3c573322be3c7f8d
5ddf9fc460c4fc4b8374e5d237680b06
61c5c4d545470711369a0ccea105b9f1
7f8c5faa7aa7e3c307d56bacce9909af
9e746e6763448df16cbc3238ccd2feda
a6fcdffbccea839edb47f3e2e16e1b0c
acf8842bec894849e599a17a9f7097a2
af540016121778b52689c9d1f2b8bafe
c074a788968777c6dc62a914ef90a3ed
c10c636e9687dce9e8b6cabf9a66c4f1
c520a8fa7d3c753cd23e845767c39202
ccca0f359d3d79c1a2ea7ce9f5d54879
d2b6bb7149561756ce4160f78a77f85e
d3eecb124513fedbb0e0786ccda0c656
ebebd26b8e70f4985600efa95de7ac17
f194aafac4442363d27edf0c0c973d87
f513dcf07106e143facae96f3c0a8959
f7cea6272e719315f42385627d6ecee0
faa3e9bd86918e4467aac1a242e6ef01
fdd1ef9a8ff67e37d97227e29a711a9a
Elise SHA256s:
016806cce6bd26791b3bdd2dd05b555b2142f402fb2f97616773c17345f4a2b5
0bca323171b01cd6bee5d923f28d15bc5b15d5afb9984a24c7498f63889ffc62
11bf1d2d32b35884347d7a44c393c3b74691742434132ff374dcdecd700d749f
19916e513c810b1aa0a86d162d3381280a8c1314635026242cb86af2cf1b9cc3
22b0308e131a152a21443d34012e18688df6ecd5a8262cf6b9d05b444a4f9bc7
260cac805fdf709b2634d9431c556bbfb7554731e1a766a2484aaebbe6d1f467
268cadedf42eb553d0ff7d0fcbbcd18c3b93a6d590d895fbbeb3b7014c4ecd17
2ae86e4e89cd86bde4e612fc9dedbcfa633cc4dd4d046a4f5d80aa85e608bdd5
2d4db05def86adeb92a65721e70105fc0497f6c2633cf7bd80485dc7bd48ebd2
2f05eda14c7e5d60d2e04aa4457f16f677f4fcfeb189a2c14ecf3c438a70f951
3bb13fa2c78dd4866c3e753a1e859cdeca2b446a8f9baa5ae8f2a062d4973971
418a89d8b047ba06575392dcf430fb901916e6005034806b43cec6a1fd1621bb
42448e3308b6f2ba180663c864ea1a6e75f7150699095a56073bb4396620fcb1
4a72a4cc8f3cdd4cc43269619beafff732742ddeca15a81822dafc56676ab073
5142086a334b07caa4d085c0ac61c9563285a820a9883279b359b21c5a9da24e
5570f04292c669e7bb65c4affcb6c4aaabe81f5df5ca6c1c438e34044b90a7f6
596e1ba536f75ec37643e1d0259aedeedc3fcd71e9a86b99955bbd51a296aacf
5f6382437be9ad658990e28e893d2fe7bf3888735ade7bb1b95d8703b0b01422
6002821057ba2df0accd13ccd133465cab150d2675c6e607a12ba463d69967cf
68bdf19e596fa3cc4b08a7743ffa23e1444be6bc9f47da35739e985e1067ae80
705c2279b3d7f9d7f21685b3251c7c850548b8274f41b798e5a5bf981e73f26d
7902569e1e64b838362a48ef756810bc3e3bb96783e8ae493b545efaaca20455
7b65e5513a0c60057517386aa026b4ad52d9af8ef3d927fcb03ac2d890dc0202
7bd110c746b3b946b69a25cdcbe7e61e81757266d14bf7e604d18457494675ce
7c617a988bcd3648478e244f67aafb68e7977ba85ee97b3254da5ae3bb0a0bdd
8a2c418e80f553667ac4c3b66b13ad6282933747175ac7c2794281b4eebb7fab
8f35cb99a0cdb8c98ebefe43b6c533c4d6a1261511f54c3b20c2c6e54273f606
9ab669eab0afb239f3d44db4b394a84309efd661af6896f55f62bf33f97ec3cb
a41eade48e93f4f44a177e7cd36ae23219de2415d163ec6abed5b40810a6251e
a812833ea49f2d1d758db88e9ee89c2ab4dacb864ef4a2373a20c0bd505e3ed2
a8278e8ebe07b3434553c8bef208ecc04fcd474382e86b9a3bb7293229e2a427
c062f8d21f0970e27b2c389aa34827c455a3cc34cb4b9d32c724f97d6177c701
c12c01907256b91f724f3d136a2c0a7ba2d68d389dd59ca87a363733feac101e
c94f80033e0906efa3cca3544d505ecccde833c3a0fbf6d65b5dbaa2ae5a4297
d102152032e25385944fcf9557299be36e155b9e59dbc612faf98f4159c8651e
d434bc7989ec691d34729347999dacbc715964cb081b015344f15d1451d17a20
de3a5f84c6c9f6068f2bdf9ec80b92f6f24aae6a06e6d7cec5835a82799b82ac
f0a15a46c8ba038e49ec98dc4b065ea1dd61c1b4e663e875ff12fb7ac950dd27
ffb011573d4d9f2a307b17df27b67ccfa643318a3a0e6ef8f145c62b3e744619
Elise MD5s:
060932c7880b6ddc704cf4ff6a4121d9
09ad967fae0e031bcbbc69d200d180ce
0c54c05ca4171e529404e4fac993c32c
1430b0595dca50a227714dc01ba792d5
16ec13572c34195214ec2bb0d9bfce48
26fe65b4c2b633ff8b65040f490e470a
2ae5ee3cac48721f3bd9e6a20bb358cf
3a2350adfb1af589cf26e23c79992d8b
3f8ef28d738d6732abd983543ddba190
43ee5edc3a5683723a116c0549ca2749
452de932d3803923f1e1c4c4c094d50b
4e73989932b3ba50f45fc72cf0b05e9b
601878431a8a7131b51779457287d9c5
62677b6664d53fdb337112730da73f5c
65abb1da7849078405e9352fe1b5dc17
6ee4c5664666fbfa80b4978ad16bcc95
7038acc604e1a2c69aa1d9c2a9fd07af
70cba4032355acde7aec3d6a5bbb2185
7fb40f038bd1b1b2e6f0127f0d53723c
815f5a52c155d1c3bcbc4f897c08d2b1
8390955f0fc751677bbf6df6dc4da370
8773c54974c33db59ee95318292d14e1
94c43b783fcc1226532058838a4b22b4
95d3546229518bd0fb5155ddf47b341f
9d2a3b1207f1cdacf4061d3e374e5a1c
9f12db080c58fdf0cc5c159352da9075
a34b48535256476c2fd1e4986519f3a6
b3dd9481bd5ad4ea38f0abf5f1c8d56d
b517dde9531481cf9f1f251aa2089829
b77311a5202a146049aaacbf48f79499
ba5d1c1f4c48427d683f94dd901a0b1b
c2c6fb0ff727025ea0a9b60f3608b0ff
ce5d5a352c37e0b4a6c7c3a332d72e59
d0b4bb84e11a8f5892f083c2e08e24f7
d6e46656fbe6e7a7b9377df63ecf3d72
d9c98bd85ce03ef851e1e0c2b5d1ab05
e633d387c4932fe18529e91fbfbd52ef
f3eb2e0c3e6e8ddb8961c61b59da2d24
f4d18d4adc6724114a189aff4b020c9f
