
Today, more devices than ever before are being developed with internet connectivity features that enhance performance and user experience, but the majority are not equipped with adequate security to protect them or the data they transmit, leaving them vulnerable to misuse.
One of the most prevalent forms of exploitation is to use these interconnected devices to create botnets – covert networks of connected devices with massive computational power that are most often leveraged for large-scale email spam operations or denial of service (DOS) attack campaigns. Several major botnets - such as Rustock, Ramnet, and Waledac - have been dismantled in recent years through partnerships between law enforcement and the private sectors. Yet, an untold number still remain active because it is extremely difficult to identify the servers that act as their command and control (C2) hubs.
It is obvious that the development of better identification techniques is required - specifically, methods to pinpoint C2 panels are needed to allow for definitive proof that an IP/domain hosting a C2 should be blocked and considered an indicator of compromise (IoC). Such a method would also be highly beneficial for botnet research and ultimately for conducting botnet takedowns.
Commonly, botnet panels are found by first observing malware activity and then identifying where exactly the malware is communicating back to. The identification process is often a manual one, requiring researchers to have already known about the C2 panel type prior to the investigation. Here, we will discuss a new method for identifying C2 panels which is automated, easy to apply at scale, and is optimized so that it requires the fewest number of requests, thus making it less apt to alert a botnet operator that the C2 panel has been discovered.
Introduction
Identifying botnet command and control (C2) panels is a difficult problem that can be solved with machine learning. While machine learning can be a difficult topic to master, it introduces an entirely new level of problem-solving tools which are invaluable to a hacker or engineer.
I was first compelled to tackle and apply machine learning to a wider set of security tools after experiencing the power of it first-hand. This tool and others were presented during our Black Hat USA 2016 talk. The GitHub repository for this project can be found here, and the Chrome extension for this project can be found here.
Identifying Botnet Panels
When hunting for botnets, as security industry folk like myself often do, we often discover C2 panels that are not immediately identifiable. While in instances such as with DiamondFox, where the authors chose to identify the panel’s true purpose, the majority of authors usually attempt to obscure their intent.
For instance, the login page for Zeus looks like a benign, nondescript login page:
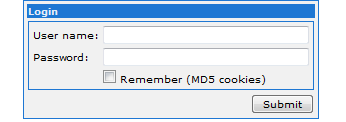
Figure 1: Zeus Login Page

Figure 2: DiamondFox Login Page
In many cases, botnet operators will modify the C2 panels to throw off even the most knowledgeable of researchers, making them difficult to identify even if the researcher has an encyclopedic knowledge of these panels.
It’s reasonable to expect that the botnet operators would not go through the effort of rewriting the entire panel, so some similarities should still remain. These similarities are likely to be found in resource files that botnet operators would not expect to betray the purpose of their page.
Machine Learning vs. Botnet Panels
We can use machine learning in combination with fuzzy hashing to make a resilient classifier, which is optimized to make as few requests as needed in order to identify these botnet panels – whether they have been modified or not.
From a machine learning perspective, this problem presents many interesting challenges. The largest issue is the limited number of known live and operational botnet panels. Historically, many have been known to be active, but there are few known live and operational panels at any given time. This is because in the majority of cases, once a panel is discovered, it's just a matter of time before it is taken down.
The scarcity of active samples to test against makes classification difficult, as the more information we have, the better. Additionally, since this is an adversarial problem, our classification method needs to be resilient to the botnet operators’ tactics to avoid detection. This means we will likely want to have some form of redundancy in place.
Finally, we want stealth and efficiency, which means making as few requests as possible. Therefore, we need to minimize the information we are using to make our classification, which requires us to strike a delicate balance when dealing with the adversarial side of this problem.
The botnet panels identified with this method are:
- Andromeda
- ;Betabot
- Citadel
- Cythosia
- Dendroid
- Dexter
- DiamondFox
- Ice IX
- JackPOS (Easter variety)
- Pony
- Solar bot
- VertexNet
- Zeus
Gathering Features and Samples
One of the most important and difficult components of integrating machine learning into a real world problem is feature engineering. Features, which are commonly represented as values between 0 and 1, are values extracted from the data which are intended to be fed into the machine learning algorithms.
In many cases, the difficult part of this process is identifying the relevant information which generalizes across all of your samples (data points), and provides value to classification. In our case here, we are looking to create features based on the results of requests we make to the website in order to determine if it is a C2 panel or not.
In order to build our feature set, we needed to identify all offsets we know to be related to botnet C2 panels, so we created what I prefer to call "prevectors." For each sample in our training set (a set of URLs we had already identified as either botnet panels or not botnet panels), we made requests for all known offsets. This is really noisy as it produces thousands of requests per panel.
To clarify, for each panel in our training set (botnet or not), we made requests for every known botnet offset/page. We stored the HTTP response code along with the ssDeep (fuzzy hash) of the content returned using these results. This allowed us to confirm that the status code is the same, as well as comparing the content without the need to actually store the content. The resulting score from the ssDeep comparison acted as the numerical value for the features, given that the response codes match first.
Once we had the prevectors for each of our known botnet and non-botnet panels, we needed to reduce the number of requests by looking for duplicate results. If, for a given request, the response code is the same and the ssDeep value is a 100% match, we remove the redundant feature.
Once we reduced the set of features, we began the process of converting our prevectors to vectors. For those unfamiliar with the term, vectors in the machine learning space are one-dimensional arrays of values representing the features extracted from samples. When converting a sample to a vector, we process each feature in the same order, and update the value in the vector to match the result of that feature.
Once we have our set of vectors generated, we can store them with their "labels", which are a numerical indication of which botnet panel (if any) was present:

Figure 3: Generating Vectors for Samples
Training
Now that we had our vectors and their associated labels, we divided them into a training set and a testing set. Roughly 80% of our samples went into our training set, and the remaining samples were used as our testing set.
We needed to ensure that each of our labels was represented in both the training and testing sets, and while this is an easy thing to ensure for a problem such as this, it is an extremely important step and must not be overlooked. If we failed to include samples from each label in each set, we would be unable to teach the model to identify that label, or to test the accuracy of the model after it was built.
In our case here, we chose to use an ensemble of decision trees in order to meet our set of requirements. Decision trees are simple classifiers that make binary decisions on each feature in order to best separate the training data into groups containing mostly (or completely) one label. Decision trees have the strong benefit of being able to make decisions based on a very small number of features, and therefore provide us with information about which features are actually needed.
Unfortunately, they have a tendency to over-fit, which means that they tend to learn too strongly from the training data and often do poorly against the testing data. For this reason, we ensembled multiple decision trees (train multiple decision trees and then have them vote on an answer), which helps to avoid overfitting:
Figure 4: Decision Tree Example
Classification
Once our model is built, classification is simple. We make all the requests that are listed in the relevant features from each decision tree, and create a vector that only fills in values for those samples.
Once the vector is built, we can pass that into all of our decision trees. Each decision tree will produce a prediction for its assigned label, and the votes for each label are collected and combined. The most dominant label (i.e.: the one with the most votes) is then considered the prediction. Due to the adversarial nature of the problem, the user is also presented with a confidence level, which indicates how strongly that label was voted for.
For example:
VIDEO: Command Line Version of ID Panel
Chrome Extension
Generally, when hunting botnets in an operational security safe VM, I work in a browser, inspecting and searching pages in order to identify them. For this reason, I've built a Chrome extension integrated with this model to automatically perform this classification on any website I visit.
When visiting a new website directory, it will automatically perform the requests in order to make the classification (less than 40 requests), and will alert the user if any indication of a botnet is discovered. Results are also stored to ease the process of referencing past results.
Learn more here:
VIDEO: Identifying Botnet C2 Panels With the ID Panel Chrome Extension
Conclusion
Botnet panel identification is a difficult problem, but it can be quickly and efficiently solved by the creative application of machine learning, a powerful tool that will only become more valuable as data continues to grow. For security professionals and engineers alike, it will be extremely advantageous to at least have an understanding of machine learning for the future.
Brian Wallace
SPEAR Team Senior Security Researcher at Cylance
