Lessons from the Front Line: Proactive Monitoring
This article is the second in the series from the BlackBerry Incident Response (IR) team examining critical behaviours that either stop incidents from happening or greatly reduce their impact. The first article regarding vulnerability management can be found here.
Insight
There is still some debate in the security industry around the preventability of breaches—some say that they are inevitable, and some believe that prevention is possible. This may be a case of the industry having 20-20 hindsight vision, but prevention can be a reality in nearly every case with the right tools, processes and procedures in place to prevent a serious incident. However, we understand that enterprises are complex beasts with a history and life of their own so when it comes to prevention or detection—the answer is both.
So what causes breaches? The constant modern business requirement for speed and competitiveness certainly increases the risk of gaps forming within an organization. Security gaps have many causes. They can be a result of too-rapid prototyping, imperfectly executed mergers and acquisitions (M&A), or the desire to be first to market at all costs. Whatever the root cause, attackers seek to take advantage of these gaps. If they are successful, then the earlier we can detect the attack in the cyber kill chain, the better things will pan out for the affected company in terms of business impact and remediation time/costs.
This article provides real-world examples and lessons learned, along with some pro-tips for proactive monitoring.
Introducing the Cyber Kill Chain: A Real-World Scenario
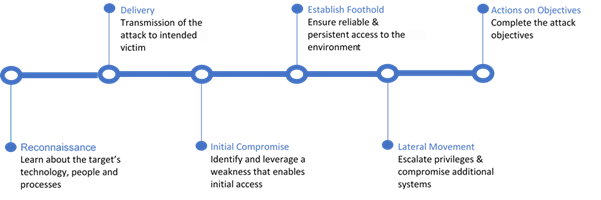
The cyber kill chain shows the various stages an attack progresses through before a breach eventually occurs—see Figure 1 below for an example. An attack detected before the initial compromise can be a manageable event; once an attacker has moved towards the right of the cyber kill chain, however, the job of containing it becomes exponentially more difficult and more expensive:
Figure 1: Cyber Kill chain showing stages that can be detected through proactive monitoring
To give an example, we recently investigated a devastating ransomware attack that crippled much of the affected party’s critical infrastructure (Active Directory, both internal and client-facing applications, and other key systems) within an organization with a large number of endpoints. Anyone that has been through this kind of attack will understand the level of disruption to staff, customers, and the organization as a whole that a ransomware attack can cause—and especially the intense pressure such an attack places on the IT department.
In this attack, as in most of the more serious destructive incidents we see, there are four distinct phases to the attacker’s workflow:
Figure 2: Four phases of attacker workflow illustrating detection opportunities
Attackers are at their most vulnerable during the first three phases, as they are trying to stay under the radar and plan their attack. Whilst some threat actors will hit what they can as quickly as possible after the initial compromise, these attacks are often less effective than those in which a threat actor took their time (weeks or longer in some cases) to fully understand the environment and take advantage of their findings.
An analogy here would be the difference between a well-planned heist that hits the main vault of a bank, and a smash-and-grab attack where the attacker uses the brute force of a speeding car to knock an ATM out of the wall. The smash-and-grab may be harder to stop due to the speed of the attack and will absolutely ruin a day or two at the bank branch’s office, whereas the well-planned attack will have longer lasting effects against morale and financials of the victimized bank.
In the real-world case we mentioned above, the attacker was in the environment attempting to bypass endpoint controls for weeks with their only access via the initially compromised host. If proactive monitoring were in place on the host endpoint, this might have saved the target organization a significant amount of money in remediation efforts and revenue loss.
The initial entry point on this particular case (and others like it) was an Internet-exposed Remote Desktop Protocol (RDP) host compromised by a relatively simple brute force attack. Brute force attacks on administrator accounts are often an effective attack technique if the systems don’t lock out users after repeated failed attempts. From our experience, even systems with relatively complex passwords can still be compromised given enough (usually automated) guesses and an overall lack of monitoring.
Many readers may be thinking, “At least my company doesn’t have any Internet-exposed RDP.” This is a common belief. However, depending on the attack group and their typical modus operandi, one of the first questions we often ask on an IR kickoff call is, “Do you have RDP exposed to the Internet?” and the answer is almost always a hard “no”. However, once we investigate and trace the attack back to Patient Zero, it’s often no surprise when we find that pockets of exposed RDP do in fact exist within the environment.
Visibility: Anomaly Detection
Brute force attacks are not subtle and are easy to detect if you have relatively simple monitoring and alerting in place. Even with logon attempts being spread over multiple source IPs, thousands of failed logons to your default admin account should quickly raise alarms in your SOC—especially from external IP addresses if externally available RDP is not supposed to exist:
Figure 3: Example of anomaly detection using Windows event authentication logs
While the above anomaly is easy to visually detect in retrospect, unless proactive monitoring is in place, it could go unnoticed. Proactive monitoring does not only apply to brute force detection; it applies to all types of attacks.
IR Tips for Creating Effective Proactive Monitoring
- Establish centralized log collection
- Prioritize data feed ingest (logs for the sake of them is pointless)
- Prioritization example: Web Proxy, Firewall, DNS, VPN, NIDS, Sinkhole, email, email defense, endpoint
- Correlate logs for end-to-end visibility and investigation
- Build panels and dashboards that enable analyst workflow
- Augment logs with threat intelligence for easy wins
- Create high-fidelity alerting
- There is no sense in generating 10,000 alerts per day if you cannot handle them - they just become noise
- Threat hunt using lower fidelity alerting
- Continuously improve monitoring and alerting
- 24x7 coverage or core + enterprise alert management (for off hours and weekends)
- Automate the mundane
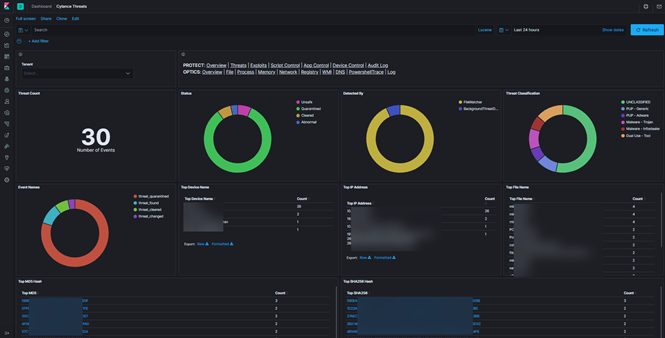
Most organizations are also investing in endpoint detection and response (EDR) tools to assist with monitoring and increased visibility. The important thing is to ensure that you have sufficient coverage using any means necessary, and the right people in place to make use of it.
Figure 4: Example of the type of dashboard that provides heads-up awareness and enough information to perform investigations.
Conclusion
Proactive monitoring takes work, and there is a fine balance between ‘too much’ and ‘not enough’. If you do not have the in-house skills and experience required, discuss managed services with your security partners, but be sure you understand the division of responsibilities, so nothing is missed.
The universal truth we have learned over the course of so many investigations is that if prevention is not possible, early detection and action is the next best thing.