Reverse Engineering Ebpfkit Rootkit With BlackBerry's Enhanced IDA Processor Tool
Any new technology can be used by malware or for otherwise malicious purposes, and eBPF is no exception. The researchers who introduced the proof-of-concept ebpfkit rootkit in 2021 demonstrated that this functionality can be used for malicious purposes. As its threat potential grows, the security community must develop new tools to respond.
eBPF is revolutionizing how Linux® applications collect data from - and within certain limitations extend - the Linux kernel. This kind of visibility and functionality used to require a kernel module, which increased the risk of “kernel panics” and deadlocks, but is now safe enough to routinely implement on live production systems. As one would expect, this has led to many new eBPF-based projects, especially in the area of networking and security functionality.
eBPF has also attracted growing attention for use in security roles such as with Linux KRSI, and it is used internally at Fortune 500 companies such as Netflix. The low overhead, safety, and visibility will make eBPF an important technology for anyone who needs to get the most out of their Linux machines.
As eBPF adoption increases, so will the need to reverse-engineer eBPF programs, but current tools are insufficient for dealing with reverse-engineering real world eBPF programs. To close this gap and make the lives of reverse-engineers easier, BlackBerry is making an enhanced reverse-engineering tool publicly available.
In this blog, we introduce an IDA processor module for the eBPF instruction set, along with helper scripts necessary for reasonable reversing. This project is currently in an alpha state, as a minimum viable tool. Much progress can still be made on it, but it’s a great step forward compared with current options we’re aware of.
Introducing the BlackBerry eBPF Reverse Engineering Tool
First up, the processor module is installed by placing it in IDA's “procs” folder, while the scripts can reside anywhere.
The “annotate_ebpf_helpers.py” script requires no dependencies, but the “annotate_relocations.py” script requires both that you have the pyelftools package installed and the original eBPF ELF (Executable and Linkable Format) file that you are reversing.
Once IDA loads and analyzes a file, the original file is no longer necessary and may be discarded by the user, but for now we need to keep it. By putting this all together, we can use IDA to analyze eBPF programs, disassemble instructions, and annotate some necessary information such as helper function calls and map references.
As an example of how to reverse engineer a complex, real-world eBPF-based application, we'll walk you through disassembling and analyzing ebpfkit. Ebpfkit is a proof-of-concept rootkit that uses eBPF for much of its functionality; it debuted at both Black Hat USA 2021 and Defcon 29. This application utilizes a complex collection of eBPF programs that cooperate with each other, including a userland component, to serve as a rootkit.
But before we dive into that, we need to cover eBPF and modern eBPF toolchains.
What is eBPF?
In short, eBPF stands for Extended Berkeley Packet Filter. Berkeley Packet Filter (BPF) was first created in the early 90s as a way to perform packet filtering in the kernel. Several years later, eBPF was introduced as a feature of the Linux kernel that was designed to enable safe and powerful tracing for performance and debugging. This is accomplished by defining a restricted virtual machine (VM) that resides in the Linux kernel, which can run eBPF programs loaded by privileged users.
These programs are attached to various points in the kernel using features like tracepoints, kprobes, and kretprobes. For example, a user-defined program can run each time a particular kernel function is called. This is incredibly useful for profiling a server, but it isn't anything a custom kernel module couldn't do. This is where the restrictions and safety come in.
By restricting what eBPF programs are allowed to do, and by passing all eBPF programs through a verifier as part of the loading process, eBPF programs can be considered safe. This means that they won't deadlock or “kernel panic” your system, and they are suitable for use on in-production servers, which is where you will most likely need to be profiling tricky performance issues and debugging rare bugs.
eBPF programs are held to some important restrictions that limit their functionality so that they can't crash or hang a system. Some of these restrictions are as follows:
- Programs are validated to run to completion.
- No unbounded loops are allowed (if loops are allowed at all, which depends on kernel version).
- Uninitialized variables cannot be used, and memory accesses must be within bounds.
- Programs are limited in size.
- The verifier must be able to verify all execution paths in the eBPF program.
Building and Loading eBPF Programs: Clang/LLVM + libbpf
eBPF programs are sent to the kernel for loading via the bpf syscall, which expects an array of eBPF instructions. Programmers can write these programs by hand, one instruction at a time, but this is too unwieldy and time-consuming for most users.
Directly using the bpf syscall also becomes unwieldy, in part because of the need to handle differences in the eBPF subsystem between kernel versions, but also due to the low-level nature of directly using syscalls. Instead, Clang/LLVM has added support for writing eBPF programs in C, and the Linux kernel provides the libbpf library to make using the eBPF subsystem easier.
Modern toolchains for eBPF programs, and the toolchain our new tool is designed against, involve writing eBPF programs in C. Recent Clang/LLVM versions are used to produce eBPF bytecode with the various transformations that the verifier would require, producing an ELF relocatable object file.
Without reading commit messages and dev mailing lists, my interpretation of the situation is that the ELF format was just a natural fit for bundling eBPF programs with necessary meta-information, because it required minimal change to support within existing tools.
These ELFs are interpreted by libbpf to handle a few different necessary tasks such as: figuring out what maps to create as well as how to load and attach the programs; making any changes necessary for the programs to work with the running kernel's types; and anything else that needs to be done.
Overall, the whole development process is much less of a headache for developers than just a few years ago. You "just" have to build the eBPF objects separately, include the files in your userland component, and use libbpf to load and interface with them.
How Do We Reverse-Engineer eBPF Programs?
This introduces an interesting problem. If we have eBPF programs loaded on our system, or which are provided to us in binary format, how do we determine what they do? As eBPF projects adopt libbpf and move towards BTF and CO-RE, we can't expect source code to be available for eBPF programs. We need a way to reverse them.
Until now, this hasn't been possible with industry-standard tools like IDA. LLVM-objdump, the LLVM project’s utility for dumping info from object files which supports disassembling eBPF, is very nice and helpful but too simple for bigger reversing jobs: It can disassemble eBPF but it doesn’t produce a call graph, allow for commenting, or provide features that users of IDA expect. Likewise, bpftool is very useful for examining the state of eBPF programs/maps/etc. on a running system, but it isn't designed for reversing these programs.
Reversing a Proof-of-Concept eBPF Rootkit: ebpfkit
We'll use ebpfkit to demonstrate how this processor module and scripts enable us to reverse engineer eBPF programs. ebpfkit builds to a Go binary, which loads and interfaces with the eBPF programs that implement the in-kernel portion of the rootkit.
Skipping the step of extracting the eBPF ELF objects from the Go binary, we can directly use the eBPF ELF objects produced during the build; they're in the ebpf/bin/ directory of the project after building. We'd eventually get them anyway, from static or even dynamic analysis, so this isn't an unreasonable thing to fast forward to.
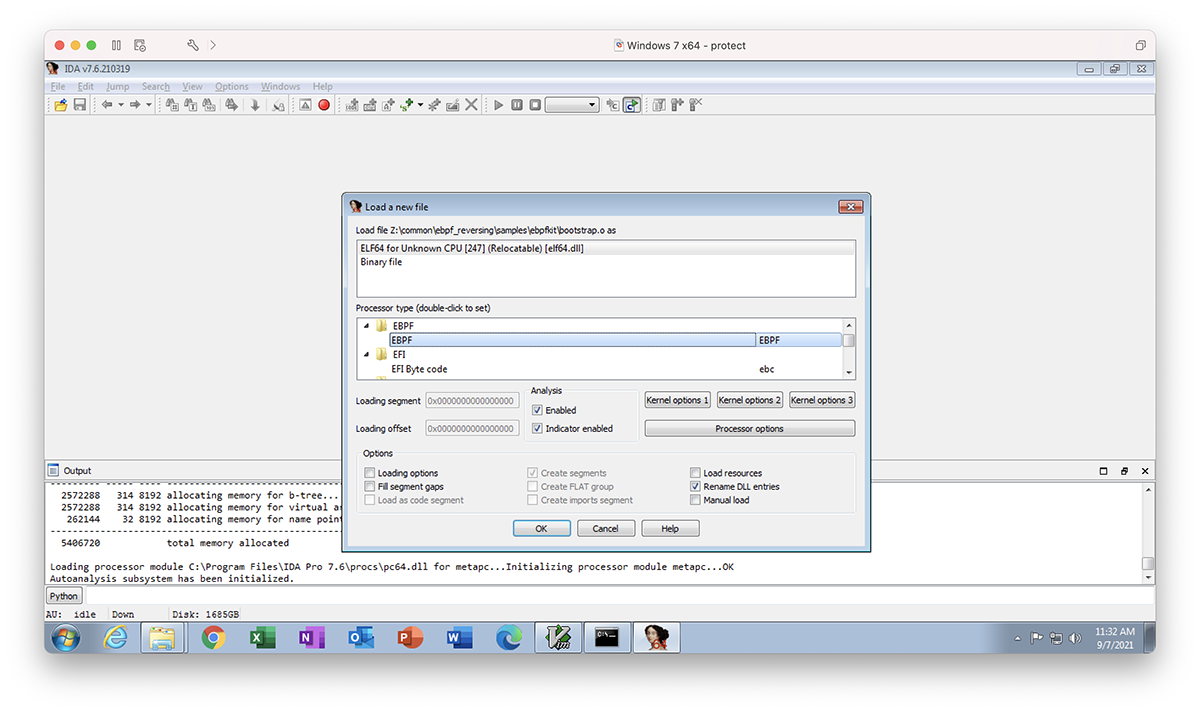
The bootstrap.o file is smaller than main.o, so let's start there. We open it in IDA, using the standard ELF loader, and select our eBPF processor. Then we click "Yes" on some of the extra confirmation/warning dialogs that come up.
Figure 1 – Processor selection dialogue in IDA
After letting the auto-analysis finish, even though IDA doesn't yet know how to fully analyze these files like typical PE or ELF objects, we immediately have some useful information. Just by looking at function names, and the sections they reside in, we can learn where each of these programs are attached, and how. We get this information because of the various conventions libbpf expects eBPF ELF files to conform to for opening and loading them.
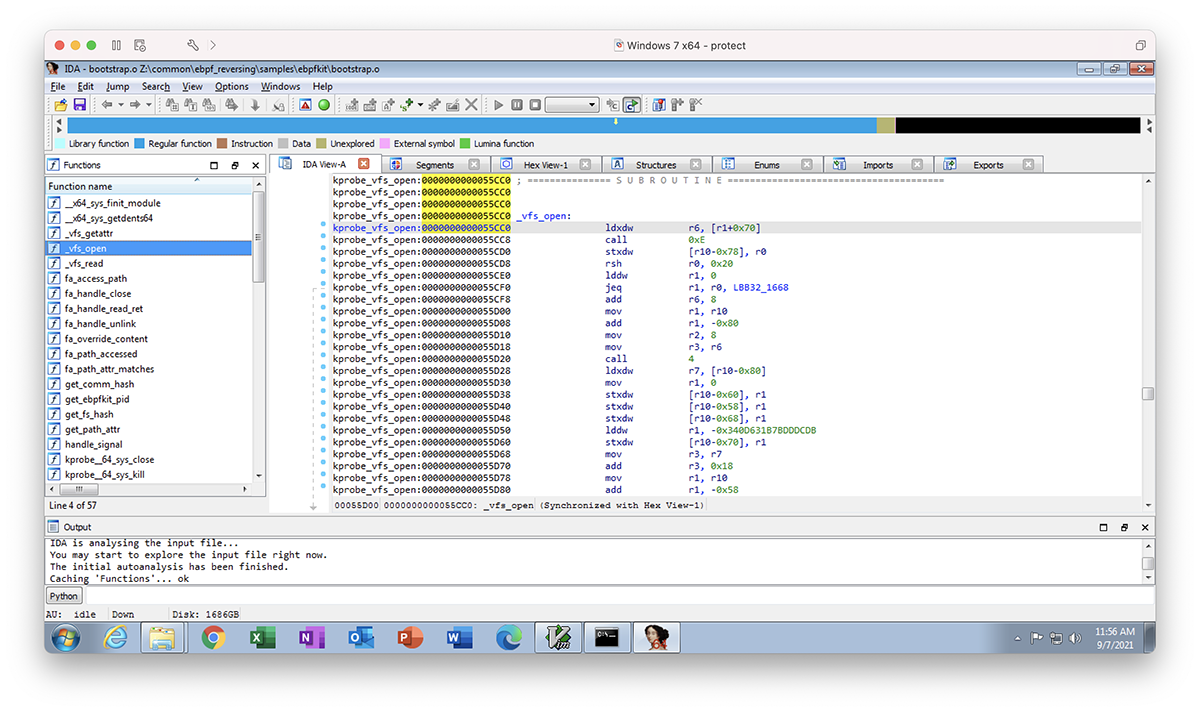
For example, the image below shows us that the _vfs_open function in the krpobe_vfs_open section is very likely to be attached to the vfs_open function via kprobe, which we can find in the Linux kernel source here, in fs/open.c. This looks like a good function to intercept and observe so we can modify all file open operations, which nearly any rootkit would need to do to at least hide itself. But this is just the bootstrap component, not the main rootkit module.
Figure 2 – _vfs_open eBPF program in IDA
eBPF Helpers
Reading the disassembly, we quickly notice that the call instructions aren't very helpful. In eBPF, most of the heavy lifting is done with helper functions. These are kernel functions that our eBPF programs are allowed to call. This is one way that the safety conditions of a verified eBPF program are maintained.
Anything that may require unbounded loops or more involved memory access can be offloaded to a kernel function. This function can be more strictly checked for correctness and safety by kernel developers, rather than allowing arbitrary eBPF programs greater access and power than they need.
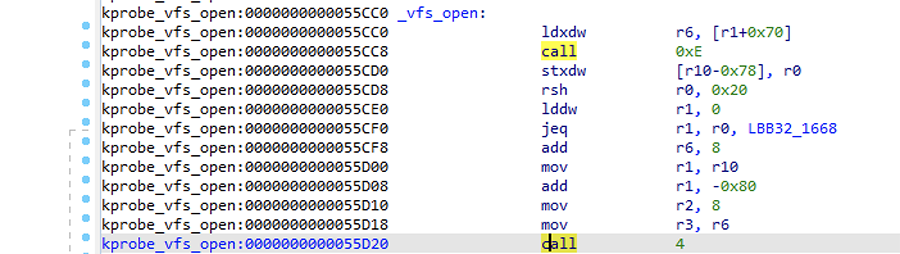
This all means that, at this stage, calling helpers with the call instruction is done by calling an integer representing the ID of the helper function. This is defined in this macro responsible for populating the bpf_func_id enum. As we can see, reading the disassembly like this isn't helpful.
Figure 3 – Unannotated call instruction
Here's where the first of our annotation scripts come in. Thankfully, the Linux kernel developers have some good tooling set up for generating eBPF helper documentation, which we can reuse to annotate helper calls. This way, we can have the full signature of the helper as a comment alongside each call, so we know what the helper function is, what parameters and types it is expecting, and what it returns. Simply go to "File > Script file..." (Alt+F7) and select our annotate_ebpf_helpers.py script.
For every function in the binary, this script iterates over all its instructions, annotating each call instruction we see. It then dumps some helpful output to IDA's output window along the way.
Figure 4 – Annotated call instruction
Now that we can see what helpers these call instructions are calling, we can determine what these parameters and local variables are. Much better!
As we dig in, the first thing we notice is that the tgid/pid combination of the calling thread is saved to a local variable. This program then saves the tgid to r0, and it loads r1 with a 64-bit 0. We then compare our own tgid with r1, and conditionally jump if they're equal.
In case you aren't familiar (I wasn't a few months ago!), there's a difference here in terminology between userland and “kernelland.” In Linux, every process has a process id (pid), and every thread has a thread id. Each thread of a process has its own thread id, but it shares the same pid as other threads in the process. But the way this is done internally uses slightly different names. Each thread has a pid but is in a thread group with other threads, referred to by tgid. So, threads in the same process have different pids but the same tgid.
Going from userland terminology to kernel terminology, what userspace sees as a pid is a tgid in the kernel, and what userspace sees as a thread id is a pid in the kernel.
Relocations for Globals and eBPF Maps
eBPF maps are key/value stores that are the primary tool for persisting variables beyond any particular invocation of an eBPF program. They're used for communication between eBPF programs, handling data outside the stack, and even limited communication with userspace. Maps are heavily used in all but the simplest eBPF programs, but they aren't allocated until runtime.
How this works is that a map is created, the eBPF programs are fixed up with the map's value, then the program is loaded. We can't know how to reference any particular map until we're loading our eBPF programs.
Similarly, there are a lot of situations where an eBPF program will need to reference a value that can't be known until the eBPF program is being loaded. For convenience, we want to treat this value as a static or global variable in our eBPF program's C source. These are both handled using relocations, where a placeholder value is used in the binary when it is built, and it’s fixed later at load time. Let's examine how this is done.
Testing PID/TGID for "Secret" Value
This comparison of the caller’s tgid against a hardcoded tgid looks like a commonly used conditional to change how we handle a system call based on what program is calling it. This often occurs because our rootkit's userland component is the one calling it and shouldn't be interfered with. But how could this be if we only ever compare against a hardcoded tgid of 0?
We can only know what tgid we want to have special handling for at runtime, long after this object is built.
It turns out that this problem is something that has existed for decades. It has also been solved for decades by binary object formats that support relocations and have loaders to fix them up. In fact, libbpf supports exactly that, and we can use this information to aid our reversing with the helper annotation script.
Let’s revisit "File > Script file..." (Alt+F7), but this time we’ll select annotate_relocations.py. This will use pyelftools to process the section headers of the eBPF ELF object, find relocations of maps and globals, and annotate them.
If the global or map has a definition that resides in the ELF file, we’ll add a data xref in IDA so we can link together other references to this data, and we can more easily link related programs to each other in informative ways. In cases where the relocated symbol is treated as an extern, we just comment it, and leave proper handling of the cross-references to a later version of these tools.
Figure 5 – Annotated global variable
Nice! With the annotated global variable, this makes much more sense.
At load time, ebpfkit must overwrite this value with the pid of its userland component. The way that this object is built, ebpfkit_pid is treated as an extern; a value that resides outside the object. We don't get nice cross-references to other locations that use it, but they'll at least be commented.
Now let's look at the rest of this _vfs_open eBPF program. This conditional is likely to make sure that any shenanigans that are done for the open syscall don't prevent the rootkit's userland component from functioning. In fact, this is precisely what happens. The true branch of that instruction has us return immediately, skipping all the other logic in this program.
Let's get a nicer look at this in graph view.
Figure 6 – IDA Graph view error message, graph too big
Unfortunately, it’s too large. One of the conditions the eBPF verifier imposes on eBPF programs is that they must end in finite time. This has actually been modified in certain ways, as eBPF has evolved. But for a long time, what this meant was that no backward edges were allowed in eBPF programs. But how would you do loops then?
You unrolled loops, and just accepted the massive bloat in program size (if it still loaded). This means that any eBPF programs that had to do string comparisons, or walk linked lists or similar data structures, had to unroll these loops. And you sometimes still had to do clever tricks to fit within program size constraints.
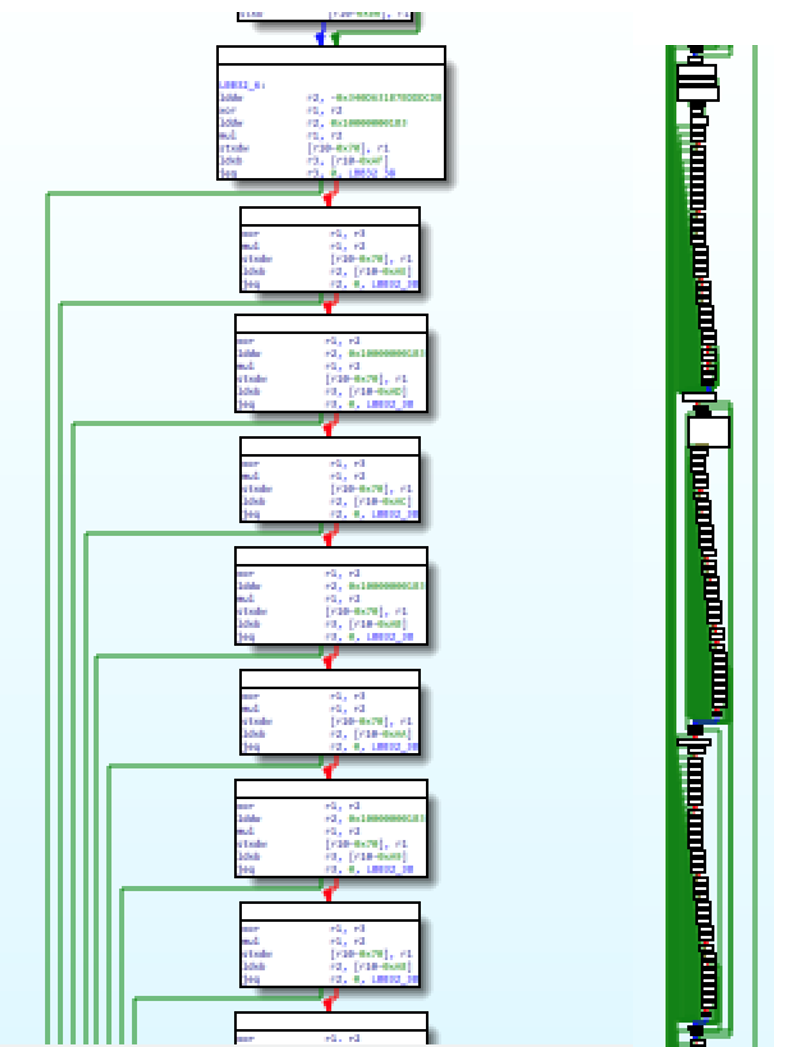
Increasing the limit to 5000 in "Options > General," then the "Graph" tab and the "Max number of nodes" field, let us use graph view. For reference, this is what an unrolled loop looks like: a conditional chain of basic blocks with repeated/identical code. Zooming out even more, we see a pattern that likely contains the code within the loop's block, and apparently contains other loops within itself.
Figures 7 and 8 – _vfs_open eBPF program in graph view, showing unrolled loop pattern
Inlined Functions
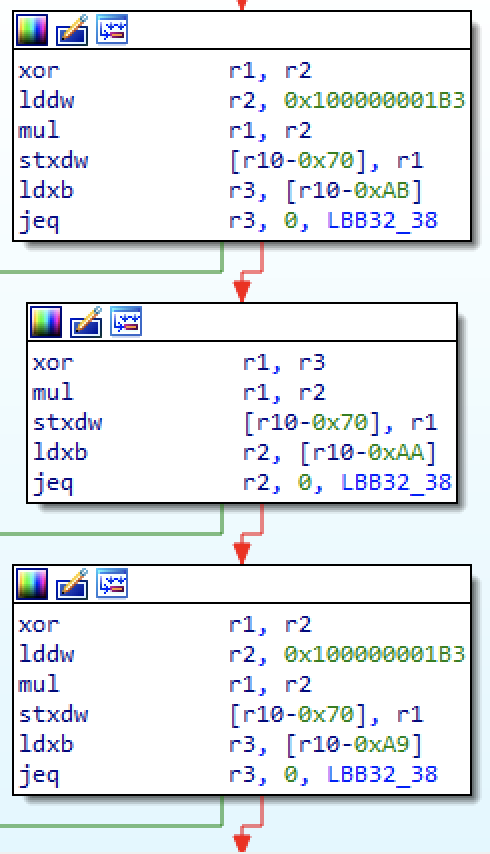
Zooming in a bit more, we see that the most repeated blocks are performing XORs and multiplications with what look like hardcoded magic values, as they walk down a buffer on the stack, with an exit condition if a zero byte is reached. This sounds a lot like computing a hash on a string. In fact, if we search for some of the bytes involved in one of the magic values, we find many other bits of code that seem to have an identical form.
Figure 9 – Hash algorithm update step, used for string comparison
Figure 10 – Other possible inlined hash calculations
Examining the matching functions, it appears that some of these are inlined into our eBPF programs. This is another result of eBPF restrictions. We can't call our other functions from our eBPF program like we can with most other languages. The closest we can do is tail calls to other loaded eBPF programs, which is designed more for a situation where you want to dispatch to particular eBPF handlers.
But this isn't useful if we want our own utility functions to do common tasks that we might want to call from the middle of eBPF programs, or to call multiple times. So, any of our own utility functions that we write to be used in multiple eBPF programs must be inlined, which would bloat our eBPF programs even more. It seems almost like a fluke of the tool chain and build process that these inlined functions are included in the binary on their own, as well as inlined into eBPF programs.
If we spend some more time determining what portions of _vfs_open correspond to which inlined utility functions (like get_comm_hash or fa_path_attr_matches) we can better break down what this unrolled loop of inlined functions is doing. Looking at which helpers are called, and which maps are referenced would help. A script looking for these repeated chunks of instructions may be helpful as well, but I don't have one. This part doesn't sound fun or as relevant to eBPF itself, so I won't go through it.
Variable Persistence and Modifying Return Values
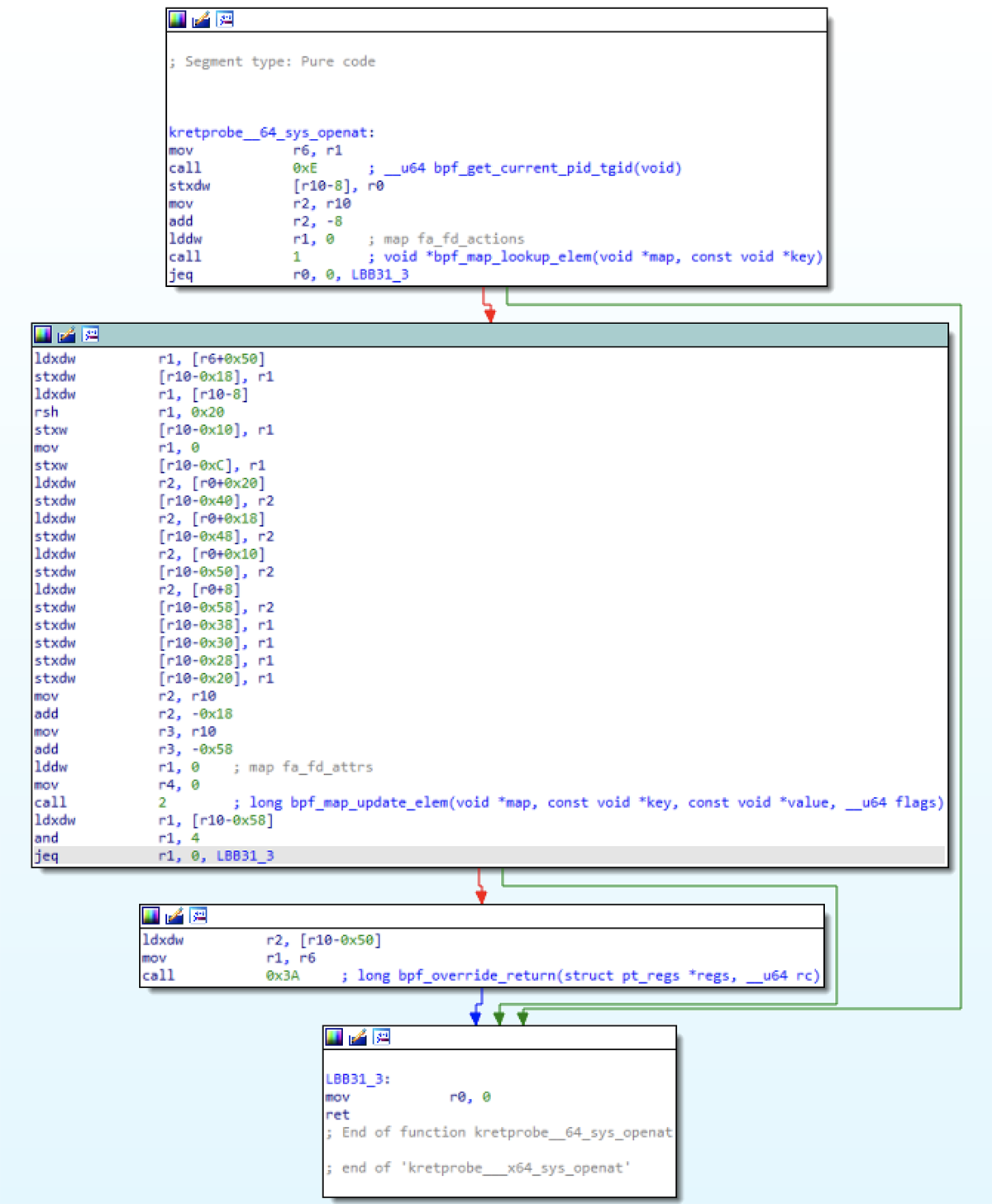
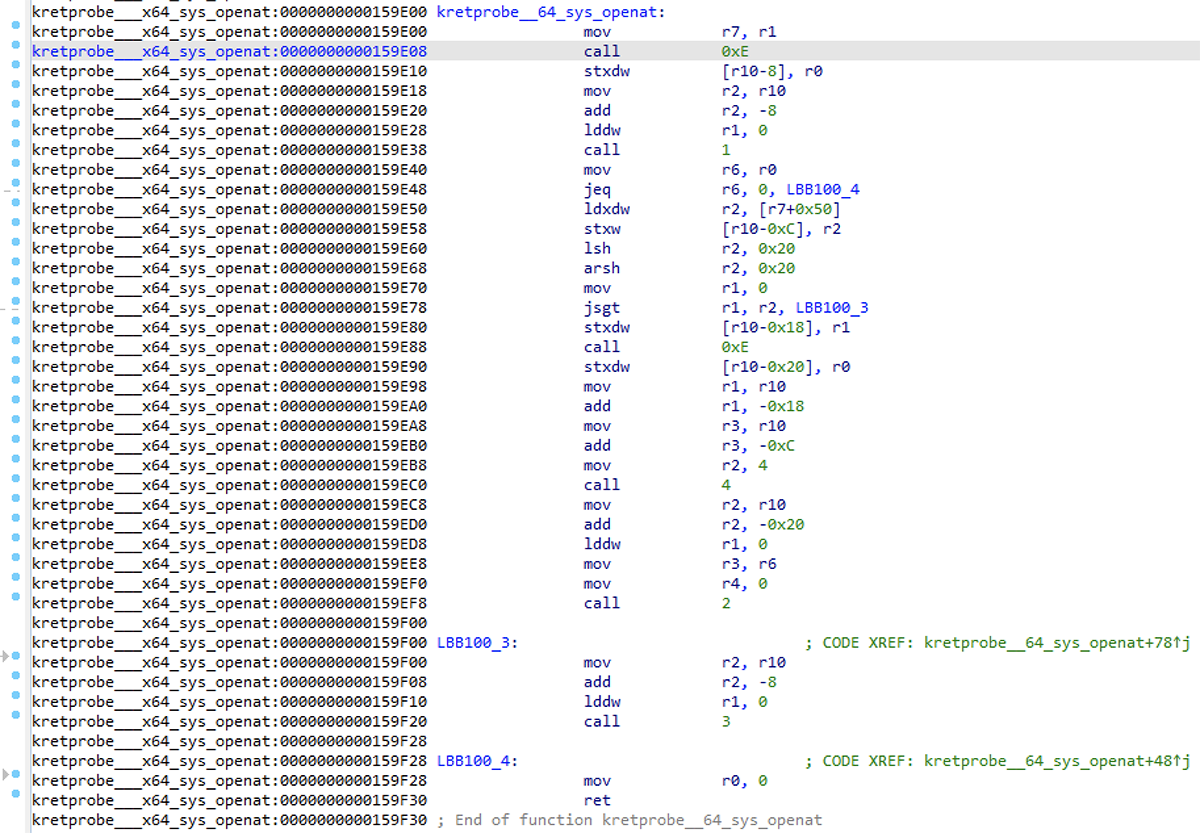
Here's a slightly nicer example of an eBPF program in the ebpfkit rootkit to reverse, with less going on with unrolled loops and inlined functions. Behold kretprobe___64_sys_openat, in the section kretprobe___x64_sys_openat :
Figure 11 – kretprobe___64_sys_openat eBPF program
We see that if we don't have an entry in the fa_fd_actions map corresponding to this tgid/pid, we skip all processing and simply return. Because we attach eBPF programs to tracepoints/kprobes/kretprobes, they behave more like small programs run on events, rather than like typical userland programs that run for extended periods and which are essentially independent of external input.
One of the consequences of this is that if we want to persist variables between eBPF programs, like a paired kprobe/kretprobe on the same function, we essentially need to use maps. If this rootkit wants to manipulate syscall parameters/results for only certain processes (e.g., not the rootkit's own userland component) then it needs to store some sort of meta-information telling kretprobes whether to do something malicious.
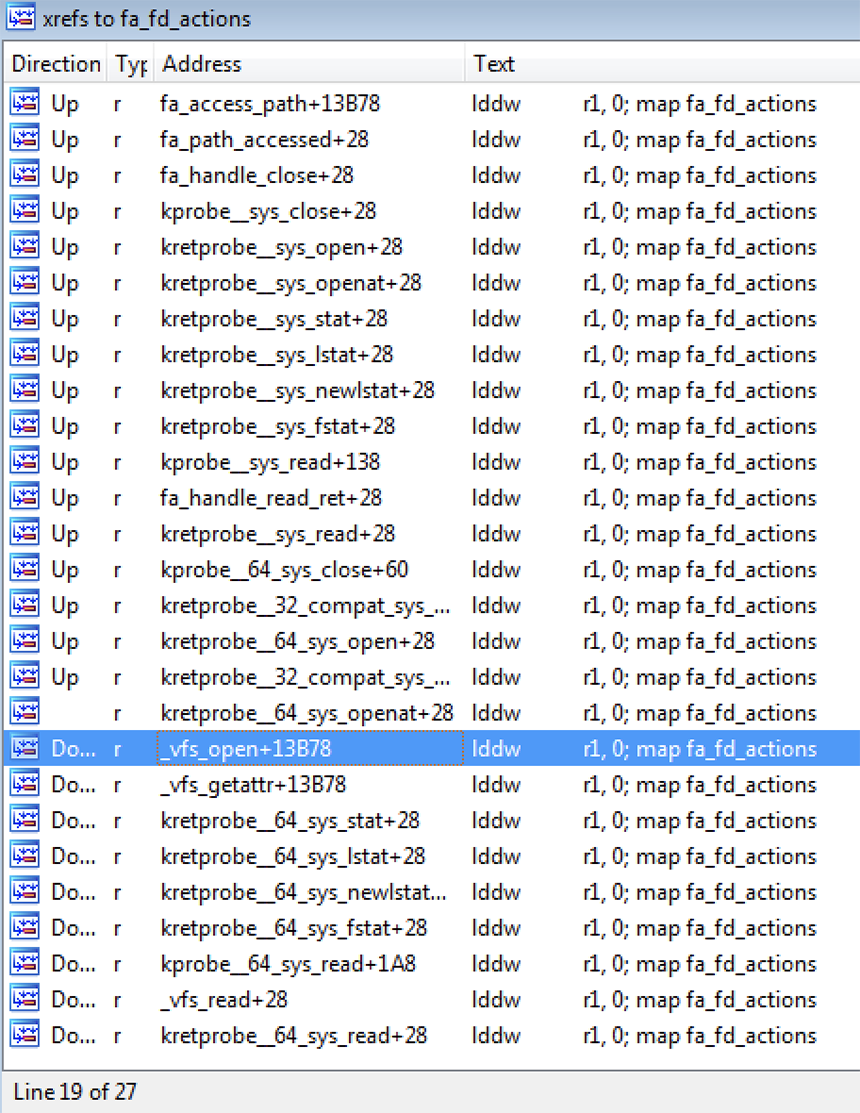
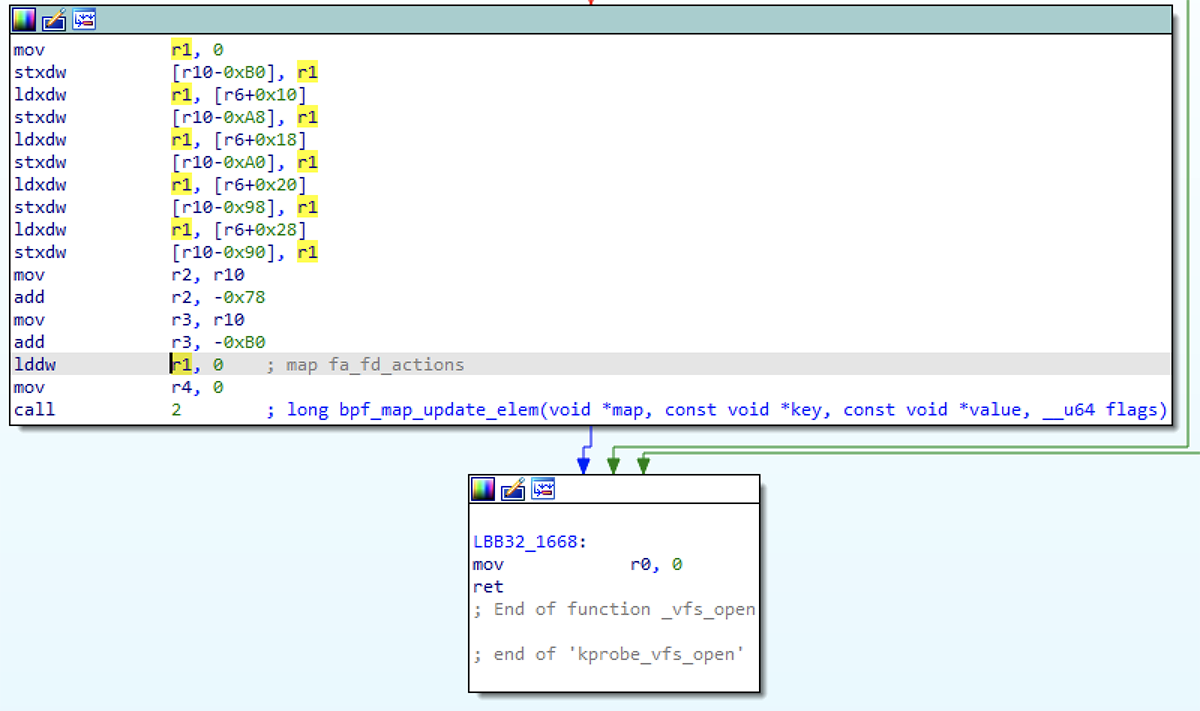
Thanks to the relocation annotating script, we can look up cross-references to this fa_fd_actions map to see where else it's used. It turns out that one of the locations it’s referenced is at the end of the _vfs_open function we were looking at earlier. This confirms my suspicion that this map is used, at least in part, to indicate to the kretprobe whether to interfere when it is invoked.
Figure 12 – Cross-references to fa_fd_actions map
Figure 13 – fa_fd_actions map update in _vfs_open eBPF program
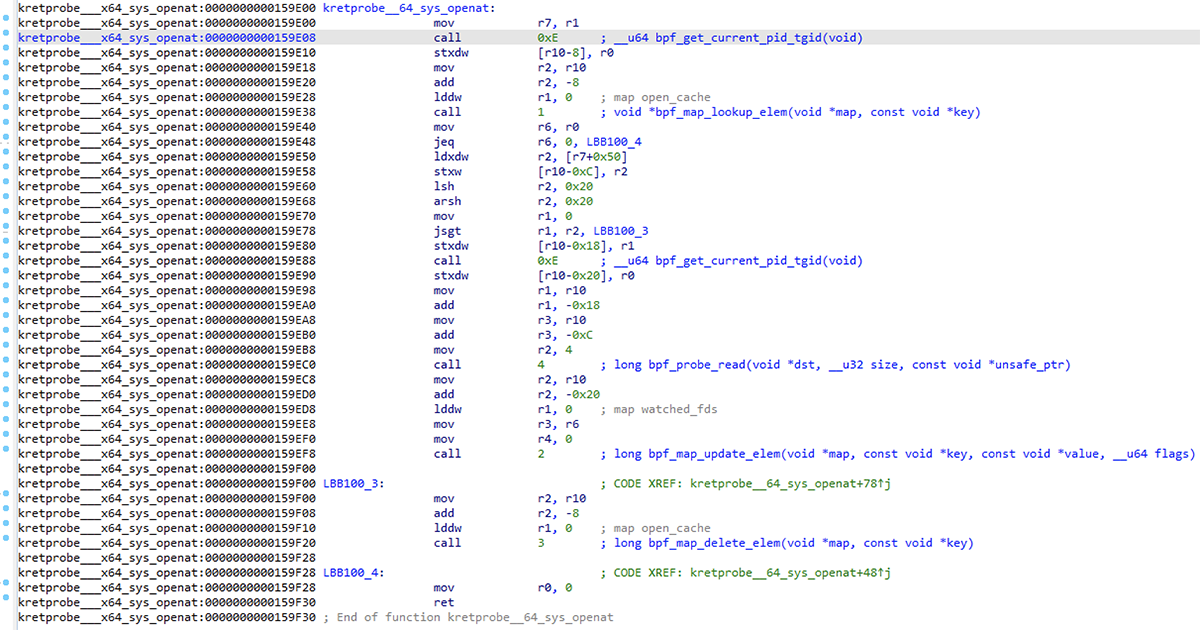
At a high level, the fd_fd_actions map is used to optionally modify the return value of this syscall. Let’s break down why in more detail.
A context parameter is passed to each eBPF program when it is invoked. This would contain register contents and thus the parameters for the function we are attached to. The sys_openat kretprobe examines the context passed to the eBPF program, which was saved to r6 in the beginning of this program. It then reads data from the fa_fd_actions element that was saved for this kretprobe, and uses this to update a corresponding element in the fa_fd_attrs map. We then test a value in our fa_fd_actions entry – specifically the 0x4 bit now stored in [r10 - 0x58] – to determine whether to call bpf_override_return. In certain cases, bpf_override_return allows us to override the return value of the function we're attached to, supplying our own return value. Just the sort of thing a rootkit might want to do.
More reversing needs to be done. But just from this, we can say that it's highly likely these eBPF programs attached to their own kprobe and kretprobe cooperate to manipulate expected syscall behavior for programs that aren't the rootkit's userland component.
Inlined Strings
There's another quirk I've noticed in eBPF ELF binaries that I would like to cover, but this bootstrap.o object file doesn't have an example of it. For this, we'll turn to main.o of ebpfkit. Following the same steps as above, we open it with the standard ELF loader, selecting our eBPF processor module, and run our annotate_ebpf_helpers.py and annotate_relocations.py scripts.
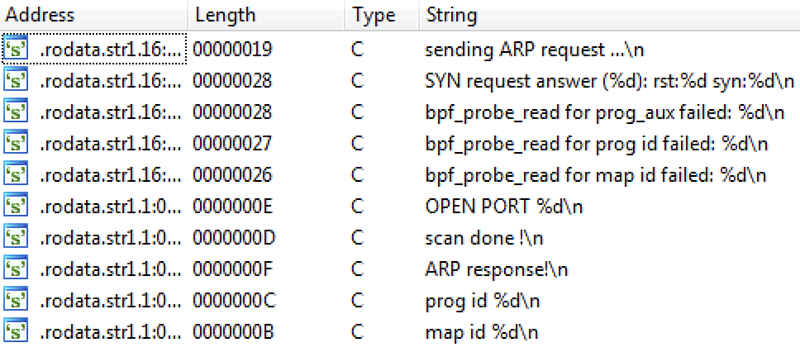
Now we look at the strings IDA knows about, by going to "View > Open Subviews > Strings" (Shift + F12).
Figure 14 – Strings in main.o detected by IDA
Nice! We should be able to use these strings to help reverse eBPF programs by learning what they're up to.
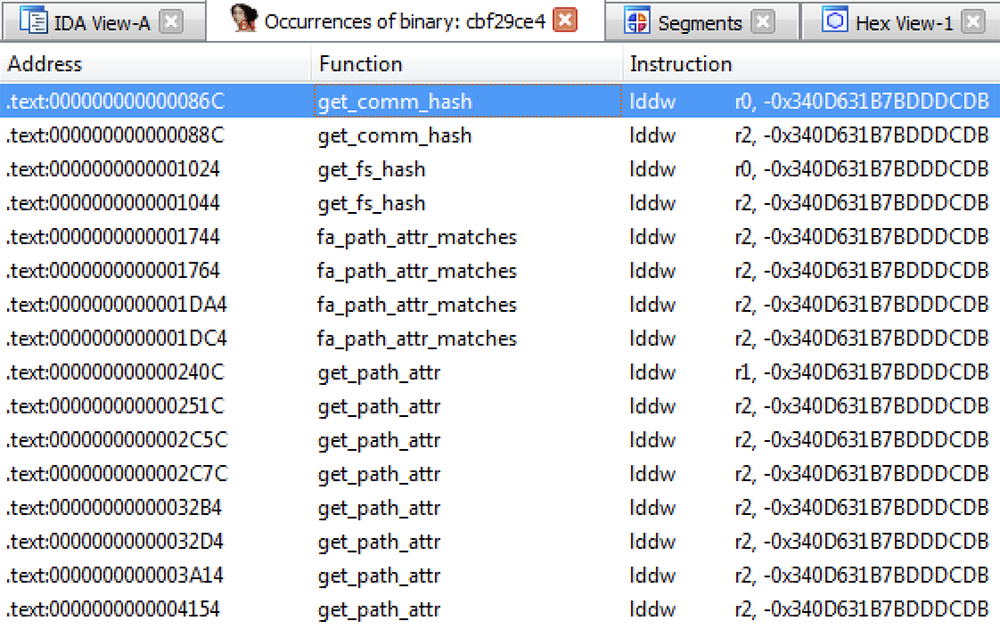
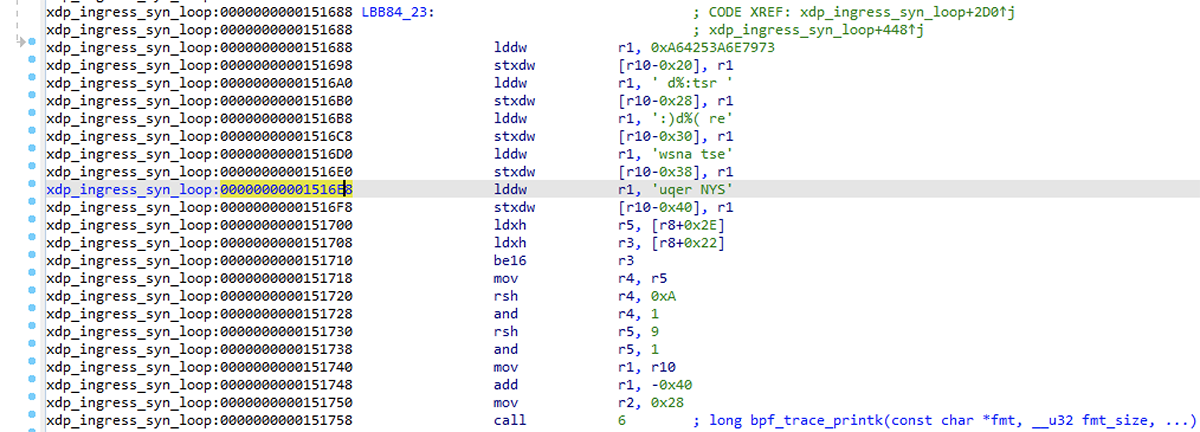
Let's focus on the SYN string. Going to its definition in the .rodata.str1.16 section, we find that there are unfortunately no known cross-references to it. The standard IDA loader doesn't know how to handle the architecture of this ELF file, and our relocation annotating script either missed this case, or there was no relocation for this data.
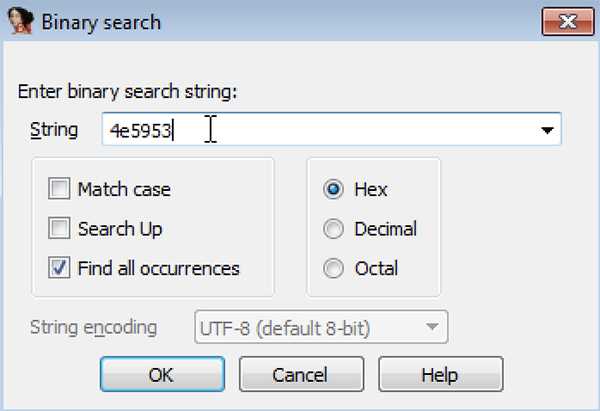
Let's go to "Search > Sequence of bytes..." (Alt + B) while viewing disassembly to search for the hex byte sequence 53 59 4e, which corresponds to "SYN" in ASCII encoding, and backwards.
Figure 15 – Searching for bytes corresponding to “SYN” in ASCII encoding
Figure 16 – Results searching for “SYN” ASCII byte sequence
Figure 17 – Only other existing match for “SYN” ASCII byte sequence, in the immediate of an instruction
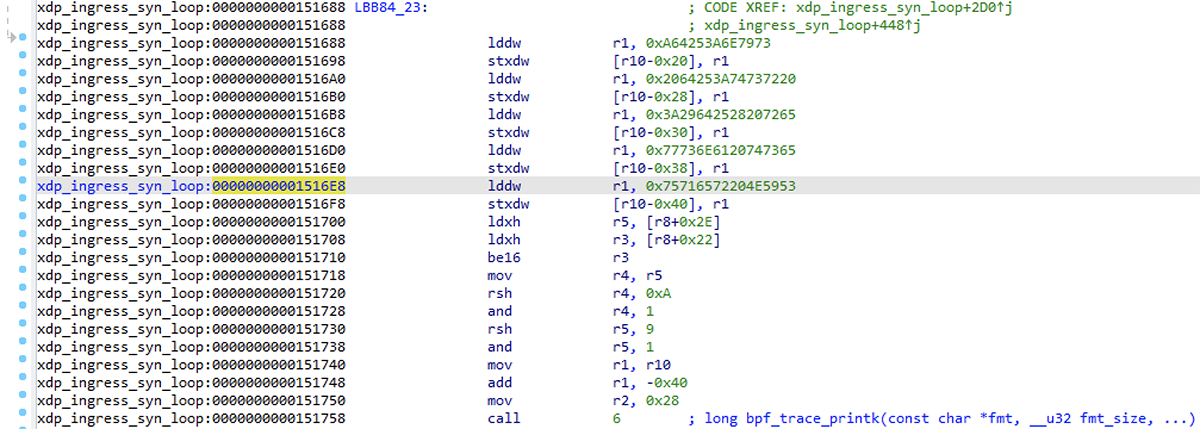
Interesting! We have only one other match in the whole binary – in the xdp_ingress_syn_loop section – with a function of the same name. Looking at the matching bytes, they're in a 64-bit load immediate instruction that is used to build a string on the stack for a bpf_trace_printk call. Using the "R" hotkey to interpret these immediates as strings makes this clearer. This is currently a bit finicky, and it doesn't always like to interpret the last portion as a string.
Figure 18 – Interpreting instruction immediates as strings in IDA for improved readability
Just as a sanity check, let's see what llvm-objdump thinks of relocations for this section:
$ llvm-objdump --reloc ../ebpfkit/ebpf/bin/main.o
...
RELOCATION RECORDS FOR [xdp/ingress/syn_loop]:
00000000000000d8 R_BPF_64_64 tcp_ip_scan_key
00000000000000f8 R_BPF_64_64 network_scans
0000000000000278 R_BPF_64_64 network_flows
00000000000002b8 R_BPF_64_64 network_flow_next_key
0000000000000318 R_BPF_64_64 network_flow_keys
0000000000000338 R_BPF_64_64 network_flows
0000000000000368 R_BPF_64_64 network_flow_keys
00000000000003b8 R_BPF_64_64 network_flows
00000000000003f0 R_BPF_64_64 network_flow_keys
0000000000000430 R_BPF_64_64 network_flows
00000000000008e8 R_BPF_64_64 network_flows
0000000000000928 R_BPF_64_64 network_flow_next_key
0000000000000980 R_BPF_64_64 network_flow_keys
00000000000009a0 R_BPF_64_64 network_flows
00000000000009d0 R_BPF_64_64 network_flow_keys
0000000000000a20 R_BPF_64_64 network_flows
0000000000000a58 R_BPF_64_64 network_flow_keys
0000000000000a90 R_BPF_64_64 network_flows
0000000000000af0 R_BPF_64_64 tcp_ip_scan_key
I see nothing about a string involving "SYN" or debug output there. These relocations are all just maps. It looks like the strings are indeed just directly inlined by the compiler. The few instances of strings being used that I've seen (mostly for bpf_trace_printk calls) are done the same way.
If we want to make use of strings for reversing, we'll need to do some byte searches to find them embedded in instruction immediates. This means we must be careful to search for sequences that won't be split up between instructions. In fact, even within an immediate, the bytes are split up.
We can see this by going to "Options > General," the "Disassembly" tab, and then setting "Number of opcode bytes (non-graph)" to 16 – the maximum width of an eBPF instruction. Cross-checking this against how llvm-objdump -dr displays the same block of code confirms the instruction bytes are displayed correctly, and that there are gaps of null bytes. Referencing the Linux kernel's built-in eBPF disassembler, the extra 64 bits in the lddw instruction are treated as another eBPF instruction where only the immediate field is used, so the other bits are left as zero.
Figure 19 – Detail of 64-bit load eBPF instructions (lddw) used for string inlining
Conclusion
This obviously isn't a full reversing of ebpfkit, as much as it’s an overview of the process, and a demonstration that it's possible. A proper reversing job would continue by identifying where all the maps are referenced, determining if perf/ring buffers are used for output, and identifying where programs are attached.
From there we can determine a few other things such as: how these eBPF programs use maps to communicate to each other, how exactly these eBPF programs inspect data when they run, and if or how they attempt to modify data or behavior at all. We can quickly tell if something seems fishy, but it would take a bit more work to determine how exactly any malicious behavior is done. For example, whether files/processes are hidden, if data is leaked, what kind of communication channels exist, etc.
Visibility into compiled eBPF programs is going to become increasingly important, and until now the only options I'm aware of for reversing them have been unsatisfactory. ebpfkit poses an excellent example of this because it’s a very interesting and complex rootkit that heavily leverages eBPF for its functionality.
There's still a long way to go, but I think this is good progress for being able to reverse real-world eBPF programs. I've also tried to cover some of the peculiarities of eBPF programs that any reverser would need to know.
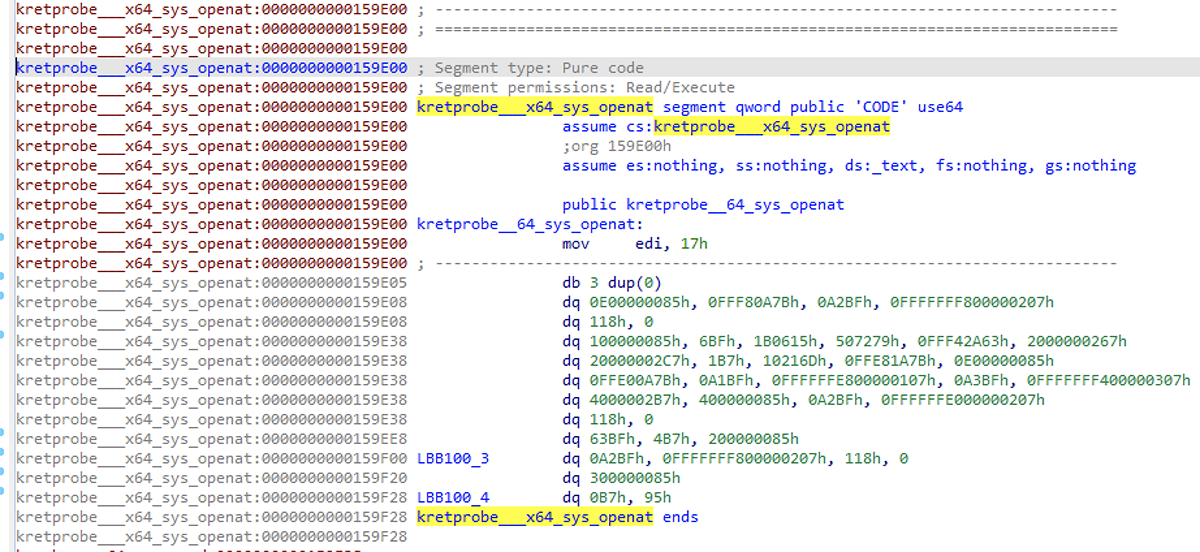
To conclude, here's some before-and-after screenshots of the kretprobe__64_sys_openat function in ebpfkit's main.o object. The first image is without the eBPF processor and just using the default MetaPC processor. The next is with our eBPF processor. The third image is with the eBPF processor and annotation script output.
Figure 20 – Unsuccessful disassembly with an incorrect processor module
Figure 21 – Successful disassembly with our eBPF processor module
Figure 22 – Successful disassembly and annotations of helper calls, map references, and global references
Future Work
We may not continue working on this project, but we do have ideas of what directions this project can head in. We’ll leave this information here for any future users interested in improving the processor module.
Starting from this work, someone could build a proper IDA loader to provide better support for eBPF ELF files. This would need to handle their specific relocation types, and ideally the BTF information they may come with. This way we can get all the cross-references and annotations our scripts currently provide, but in a more robust way. This would allow for more robustly handling extern symbols. Even better, a dedicated section could be added for eBPF helpers as if they were also externs, so we could have cross-references for them instead of just comments.
The libbpf source would be a very detailed and informative reference for this, as it serves as a de-facto definition of how data in the ELF is interpreted for loading eBPF programs.
Additionally, it could be possible to use BTF information to add known structures or annotate accesses to a struct's fields, but I have not researched this at all.
Additionally, someone could build a separate loader and dumper to support analyzing programs loaded on a system. They would need to write a program that uses bpftool (and possibly libbpf or something similar) to dump loaded eBPF programs from a system, along with other necessary information like maps, and package that all up in a reasonable format. The accompanying loader would then use this bundle to load the programs into IDA, create map definitions, add cross-references, etc.
If a system is compromised by something like ebpfkit that actively tries to hide its tracks, and which will hide its maps and programs, this will be of no use. But it would still be useful for reversing more typical applications.
Tools like Volatility and their recent support for Linux's tracing framework would need to be used to sniff out rootkits on a compromised system, possibly alongside this eBPF processor module if eBPF code is encountered. But it's just as likely that the JITed version of a program would be available, with its own reversing quirks.
Though every instruction in the ELFs we've tested against is now recognized, not all instructions are handled by the processor. In the event that a binary uses an eBPF instruction that's currently unsupported, kernel source would need to be referenced to add support for analyzing and disassembling the instruction. Also, more work needs to be done on emulating the stack and defining variables to aid in analysis.
Finally, it would be wonderful to see similar work done for Ghidra, so this functionality can be available for more users. Hopefully this project can be a helpful reference for how to load, analyze, and disassemble an eBPF ELF file.
Homework
Here’s something you can do to give this project a test run if you’re interested in getting hands-on but don’t have any eBPF projects of your own. Try using this processor module and scripts to reverse some of the programs in this repository: https://github.com/pathtofile/bad-bpf. Everything should work fine, but it has not been tested, so if you run into any problems, please open an issue on the eBPF processor repo, with the sample eBPF ELF file that causes the problem.
Reversing the Go Binary (Exercise for the Reader)
ebpfkit builds to a Go binary with the eBPF ELF binaries embedded in it, to be updated and loaded at runtime. I haven't spent much time reversing this process to demonstrate precisely how to extract these from the binary, but here's some info to start with.
Examining source, we see that ebpfkit uses this package to pack the eBPF ELF files into the final binary: https://github.com/shuLhan/go-bindata/.
Using binwalk, we do indeed see that the beginnings of each gzipped ELF object reside in the .noptrdata section. However, this is only the beginning of the files, not the full files. We'll need to do more reversing and analysis to determine how exactly to pull this data out. But it's conceptually possible, there's no extra obfuscation of the objects, and the program itself is able to extract them.
ebpfkit's Cilium-based Loading Alternative
Another quirk of ebpfkit we didn’t directly deal with was its eBPF ELF loading process. Reading the source for ebpfkit, we note that it uses a fork of Cilium for fixing up and loading eBPF programs, not libbpf. But it still uses Clang/LLVM to build the eBPF programs into ELF relocatable objects, and it parses these ELF objects in the loading process. So even projects that do not use libbpf should still have objects we can analyze if they use Clang/LLVM to build their eBPF programs.
The power of writing eBPF programs in C and building with Clang/LLVM is enough to make this a great choice for any complex eBPF project. Thus, it’s likely that any real-world need for eBPF reversing would involve eBPF ELF objects loadable by libbpf, regardless of whether libbpf is actually used.
Thanks:
I'd like to thank the rest of the Applied Research Team for all the help with eBPF internals, the IDA Pro API, and feedback on the tooling and writeup. I'd also like to thank Clément Berthaux, the original author of the plugin. Being able to start from existing work saved significant time and effort.
References
Here are some deeper references for eBPF and eBPF reversing:
Here are some eBPF programs to build and reverse:
These are a bit more general and intro-friendly:
For similar articles and news delivered straight to your inbox, subscribe to the BlackBerry Blog.
About Michael Zandi
Software Engineer Associate of Applied Research at BlackBerry.
About The BlackBerry Research and Intelligence Team
The BlackBerry Research and Intelligence team is a highly experienced threat research group specializing in a wide range of cybersecurity disciplines, conducting continuous threat hunting to provide comprehensive insights into emerging threats. We analyze and address various attack vectors, leveraging our deep expertise in the cyberthreat landscape to develop proactive strategies that safeguard against adversaries.
Whether it's identifying new vulnerabilities or staying ahead of sophisticated attack tactics, we are dedicated to securing your digital assets with cutting-edge research and innovative solutions.