Predictive AI in Cybersecurity: What Works and How to Understand It
Here is what matters most when it comes to artificial intelligence (AI) in cybersecurity: Outcomes.
As the threat landscape evolves and generative AI is added to the toolsets available to defenders and attackers alike, evaluating the relative effectiveness of various AI-based security offerings is increasingly important — and difficult. Asking the right questions can help you spot solutions that deliver value and ROI, instead of just marketing hype. Questions like, “Can your predictive AI tools sufficiently block what’s new?” And, “What actually signals success in a cybersecurity platform powered by artificial intelligence?”
As BlackBerry’s AI and ML (machine learning) patent portfolio attests, BlackBerry is a leader in this space and has developed an exceptionally well-informed point of view on what works and why. This blog will pull back the covers and explore this timely topic.
Evolution of AI in Cybersecurity
Some of the earliest uses of ML and AI in cybersecurity date back to the development of the CylancePROTECT® EPP (endpoint protection platform) more than a decade ago. However, predicting and preventing new malware attacks is arguably more crucial today, as generative AI helps threat actors rapidly write and test new code. The most recent BlackBerry Global Threat Intelligence Report uncovered a 13% surge in novel malware attacks, quarter over quarter. Preventing these attacks is an ongoing challenge but thankfully, the evolution in attacks is being met by an evolution in technology.
BlackBerry data science and machine learning teams continuously improve model performance and efficacy for the company’s predictive AI tools. And recent third-party tests reveal our CylanceENDPOINT® blocks 98.9% of all threats because they can actively predict malware behavior, even if it’s a brand new variant. Achieving this level of efficacy is difficult, and requires precise model training on the correct type of indicators.
Over the past decade, we have continuously innovated, experimented, and evolved our AI to produce the best outcomes. Some of the major shifts we’ve made include moving solely from supervised human-labeling in our early models to a composite training approach, including unsupervised, supervised, and active learning – both in the cloud and locally on the endpoints we protect. We’ve also optimized the attributes and datasets we utilize to provide the best predictive outcomes, after examining extremely large data volumes over time. The result of this continuous evolution has been a model that is very well fit to real-world application: One that can accurately predict and anticipate new threats.
Temporal Advantage: Taking Time Into Account
Today, discussions regarding the quality and efficacy of ML models often revolve around the model's size, number of parameters, and performance in established test data without considering the most important outcome good AI can provide: time.
In certain domains — like language, vision, object categorization and identification tasks — time is not a critical attribute for evaluation. However, in cybersecurity, time matters a great deal. In fact, time is of the essence for threat detection in the context of malware pre-execution protection. This is where models identify and block malware before it deploys and executes.
Along with making adversarial behavior predictions through machine learning, model validation must consider temporal resilience, where it proves itself effective against both past and future attacks. One of the most important metrics in this context is the model's predictive advantage over time. Temporal Predictive Advantage (TPA) is a term used within our data science team to assess the performance of our models against future threats.
This concept dates to the evaluation of security algorithms or cipher designs that measure cryptographic time invariance — in other words, whether the system's response to input is predictable and correct, regardless of when that input signal occurs.
Here is an example: Given that we cannot fast-forward or rewind time, we train the models using malware classes from the past, and test them against newer malware from the present. The goal of this temporal testing is to validate generalized performance over time, which is crucial for detecting zero-day protection. This testing helps us train the model architecture and assess its ability to learn and detect malicious intent.
It is reasonable to ask the question, “Why does it matter?” After all, models can be updated frequently in the cloud, which is typically where most models are served from. However, there are many endpoints — such as in IoT, regulated industries, or disconnected and even intentionally air-gapped endpoints — that are not cloud-connected. Updating models may not always be feasible in these cases. In ML models that are heavily cloud-dependent, a loss of connectivity can greatly decrease detection rates. However, recent third-party analysis reveals that the way we’ve built our BlackBerry Cylance model, malware detection and ongoing protection occur at the same level regardless of connectivity. We are cloud-enabled, but not cloud-dependent.
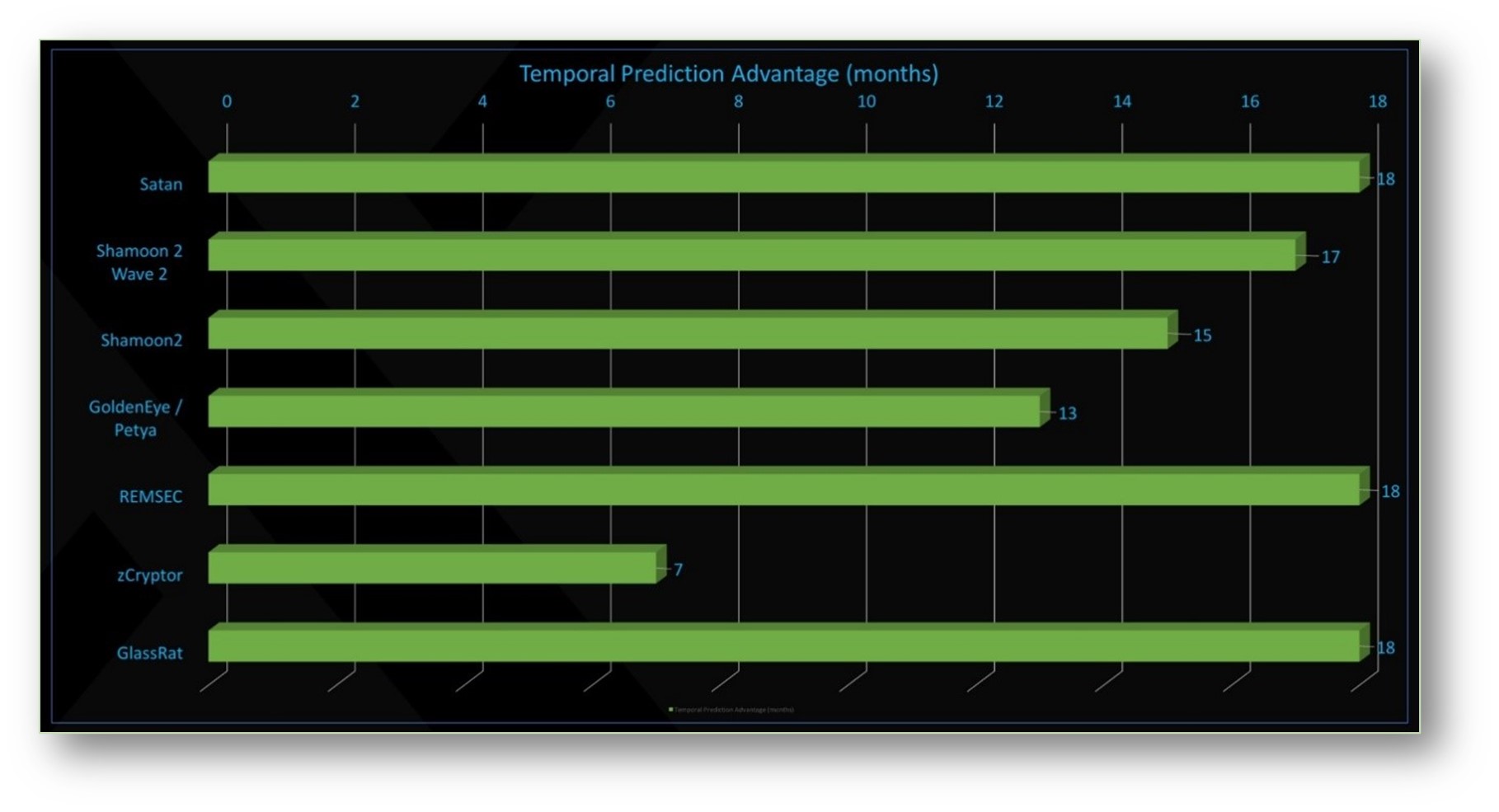
And here is a further important note: If your vendor pushes out frequent model updates, it may indicate the immaturity of an ML model. Without the updates, that model might experience faster drift — the loss of predictive power — and experience rapidly increasing malware class misses. In contrast, the chart below illustrates the temporal predictive advantage (TPA) in months, when our fourth-generation Cylance model was tested against newer classes of malware. How long into the future did it detect and block threats without a model update?
Chart 1 — The temporal predictive advantage for the fourth-generation Cylance AI model. It reveals how long into the future protection continues without a model update, in this case for six to 18 months.
The protection continued for up to 18 months without a model update. Again, this reveals model maturity and precise model training. This does not happen by accident.
Mature AI Predicts, Prevents Future Evasive Threats
CylanceENDPOINT has a novel ML model inference technology that sets it apart. It can deduce, or “infer” whether something is a threat, even when it has never seen it before. Our approach utilizes a unique hybrid method of distributed inference, a concept that was conceived seven years ago, before the availability of ML libraries and model-serving tools. The result of this approach is our latest model, which represents the pinnacle of innovation and improvements over the many generations of this technology.
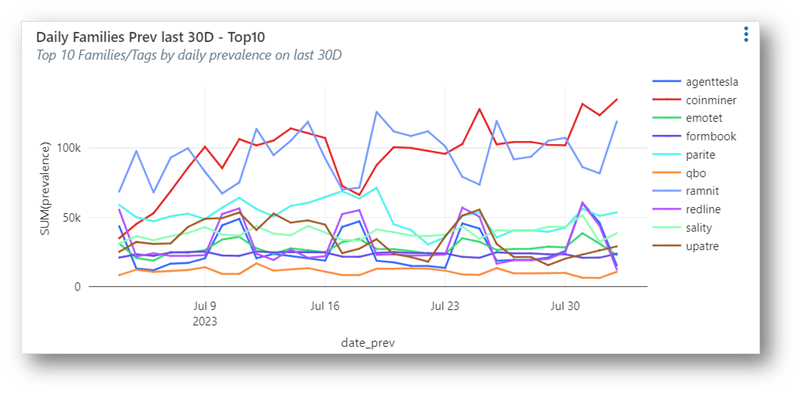
To see how mature AI detects evasive malware, see the chart below and look at the detection of Sality and Parite malware as examples. These are polymorphic malware variants, which create multiple versions of themselves in an attempt to avoid detection. These are very difficult to detect using conventional methods, such as signatures and heuristics, or with immature machine-learning methods. All AI and ML models are not created equal, regardless of how they are marketed.
Chart 2 — This graph shows 30 days of malware classes observed in our system. Some of these classes are new and updated and have not been seen before. However, the model detects them, regardless.
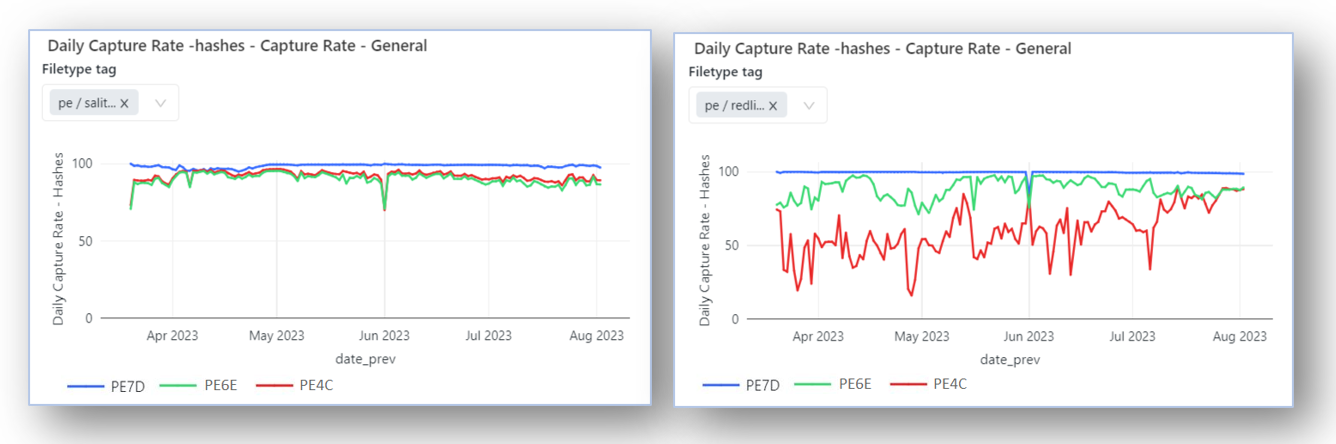
RedLine Infostealer emerged in early 2020 as a malware-as-service with high replication. It frequently hides on ChatGPT, Bard, Facebook ads etc.
Could it be readily detected? The charts below show model performance against two classes, polymorphic malware class Sality, and malware-as-service class RedLine. (Note: PE4C, PE6E, and PE7D are model generations, with PE7D being the most recent).
Charts 3a and 3b — These graphs show multiple Cylance model generations and their high conviction rates of polymorphic Sality malware (left) and RedLine Infostealer (right), even when the ML model is several years old.
Temporal predictive advantage of the models comes through quite nicely in these results. The sixth-generation model, released more than three years ago, decisively identifies, or “convicts” the malware, and our newest model update convicts over 99% of RedLine’s newer variations (in this chart, more is better).
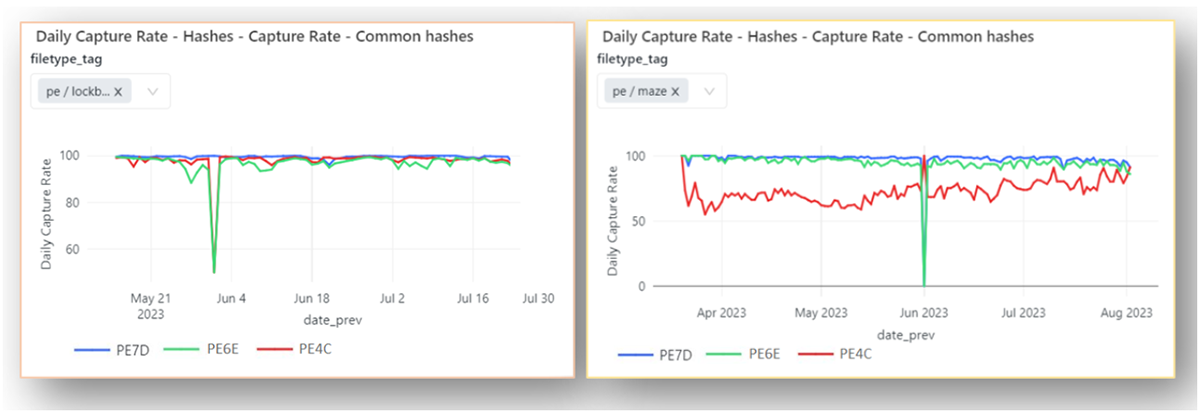
Below are some additional charts of model performance against specific classes of interesting ransomware such as LockBit (left) and Maze ransomware (right). These results show a similar predictive advantage of our ML models. It is also worth noting that our most recent model version, PE7D, convicts more than 99% of these variants.
Charts 4a and 4b — These graphs show multiple Cylance model generations and their high conviction rates of LockBit (left) and Maze malware (right), even when the ML model is several years old.
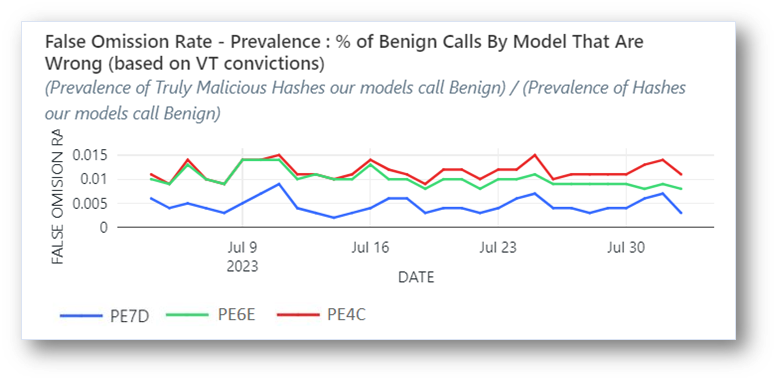
Now let’s broaden out these results and look at the overall performance of the models against all malware classes observed during a 30-day timespan. See the chart below, where less is better.
Chart 5 — This graph reveals extremely low false omission rates across various Cylance model generations. This is when a model fails to recognize malware as malicious, so lower is better.
The chart above shows the percentage of false omission. This refers to when the model does not convict a malware strain because it incorrectly identifies it as exhibiting benign behavior. A lower score is better in this case, since it captures the omission rate as a percentage of total. Our newest generation model’s miss rate is less than 0.005%, and results are below 0.01% for the previous generations, across all categories, observed over a 30-day period on recent malware types.
Predicting Malware: The Most Mature Cylance Model
With access to vast and diverse datasets, comprising petabytes of data and observed malware behaviors over time, our most recent model is also our most powerful version to date. It has outperformed all its predecessors across various performance indicators, including temporal predictive advantage.
After more than 500 million samples evaluated across billions of features, and inference results from the previous generations capturing insights over time, BlackBerry Cylance AI continues to deliver highly desirable results. And it boasts impressive speed as it supports distributed inference, both locally and in the cloud.
Our application of machine learning in cybersecurity is well established, and we are excited in our journey to drive innovation in this field. As adversaries continue to adopt AI, it is more important than ever to ensure your defensive cybersecurity posture focuses on outcomes that matter.
Cylance AI has protected businesses and governments globally from cyberattacks since its inception, with a multi-year predictive advantage. BlackBerry’s Cylance AI helps customers stop 36% more malware, 12x faster, and with 20x less overhead than the competition These outcomes demonstrate that not all AI is created the same. And not all AI is Cylance AI.
For similar articles and news delivered straight to your inbox, subscribe to the BlackBerry Blog.
About Shiladitya Sircar
Shiladitya Sircar is the SVP, Product Engineering & Data Science at BlackBerry, where he leads Cybersecurity R&D teams. In his role, he is responsible for the development of BlackBerry Cylance Threat Intelligence Cloud, ZTNA, NDR, and CylanceMDR platforms. He holds many patents and publications in the fields of machine learning, mobile messaging, cryptography, satellite imaging, and radar interferometry. Shil has a bachelor's and master's degree in Electrical and Communications Engineering from Memorial University of Newfoundland.

About The BlackBerry Cylance Data Science and Machine Learning Team
The BlackBerry Cylance Data Science and Machine Learning research team consists of experts in a variety of fields. With machine learning at the heart of all of BlackBerry’s cybersecurity products, the Data Science Research team is a critical, highly visible, and high-impact team within the company. The team brings together experts from machine learning, stats, computer science, computer security, and various applied sciences, with backgrounds including deep learning, Bayesian statistics, time-series modeling, generative modeling, topology, scalable data processing, and software engineering.
What we do:
- Invent novel machine-learning techniques to tackle important problems in computer security
- Write code that scales to very large datasets, often with millions of dimensions and billions of attributes
- Discover ways to strengthen machine learning models against adversarial attacks
- Publish papers and present research at conferences